A New Algorithm for Controlled Randomness
by Malte Skarupke
I don’t know if this problem has a proper name, but in game development you usually don’t want truly random numbers. I’ve seen the solution named a “pseudo random distribution” but “pseudo random” already has a different meaning outside of game design, so I will just call it controlled randomness for this blog post.
The description of the problem is this: An enemy is supposed to drop a crucial item 50% of the time. Players fight this enemy over and over again, and after fighting the enemy ten times the item still hasn’t dropped. They think the game is broken. Or an attack is supposed to succeed 90% of the time but misses three times in a row. Players will think the game is broken.
In this blog post I want to expand that problem to the situation where you not only have two choices (success or fail) but many choices. For example you want to create traffic on a road and spawn a bunch of random cars without having the same car too many times. The problem was already partially solved for the success/fail case, and in this blog post I will improve on that solution and present the solution for the case where there are many choices.
I will also allow you to control exactly how random or non-random you want the result to be. If you’re fine with a 90% success chance to fail three times in a row in certain situations, but want it to be more reliable in other situations, you will be able to tweak that with a number.
First of all I need to clarify that in the above examples, it is certainly the game that is broken. If something has a 90% chance of succeeding and it fails three times in a row, the player is completely justified in thinking that the game is broken. Three failures in a row are a 1 in 1000 chance, so if you have enough players, or players play your game for long enough, this will happen a lot. And you might think that players are just bad at statistics and are wrong for complaining, but the problem is deeper than that.
Most of the time when you use randomness, you don’t actually want randomness. One use case for randomness is to generate variety. For example when you don’t want the same items to drop every time. But true randomness doesn’t guarantee variety, so you shouldn’t use true randomness.
Another use case for randomness is to emulate systems that are too complex to fully simulate. For example when you just give an attack a 90% chance to hit instead of simulating the movement of the sword and the dodging or parrying of enemies and all that. But true random numbers are rarely the correct approach to simulating a system like that: If you have a 90% hit chance (like when stabbing an enemy from behind) and you miss twice, in reality you would play it safe the third time and definitely hit. You didn’t want to simulate the complexity of the underlying system, but you need to at least be somewhat close to it, and true randomness is the wrong choice as soon as a system is even slightly complex and includes a feedback loop that would react to the first two failures.
Solution for Success/Fail
For a simple success/fail case, the best solution I am aware of is the solution that Blizzard used for Warcraft 3. It is explained here, but let me also explain it with an example:
The idea is that you keep on increasing the chance every time that something fails to happen. Let’s say you have a 19% chance to get a critical hit. Then the first time you attack, and you want to calculate if it was a critical hit or not, you use true randomness with a 5% chance of succeeding. If you don’t land a critical hit, the next time you will get a 10% chance. If you fail again your chance goes up to 15%, then 20%, 25% etc. If you keep on failing, at some point you will have a 100% chance of landing a critical attack. But if you succeed at any point, your chance goes back down to 5%.
This approach does two things: 1. It prevents long dry stretches where you never seem to get a critical hit. 2. It makes it less likely that you get a critical hit twice in a row. If you do increments of 5% like this, you will on average succeed roughly 19% of the time. How do you arrive at that 5% base chance? I actually don’t know an analytic way of arriving there, but you can get there experimentally pretty easily by just writing a loop that runs through this a million times and then tells you how often it succeeded or failed. Then you build a lookup table that contains the percentages.
All that being said this algorithm breaks somewhere between 60% and 70%. From the above link it sounds like Blizzard fixed the problem by just messing with the percentages. For example in their case, when a designer puts in a 70% chance of something happening, they actually only get a 60% chance. How does the algorithm break? In order to get a 70% chance, you need to have a 57% chance on the first try, and a 100% chance on the second try. The obvious problem with that is that it can make the game predictable. Once players notice that an ability will always succeed if it has failed before, they can exploit that behavior. So I actually prefer a different approach: Instead of adding the percentages, multiply them instead.
Going through the multiplication example with the 19% chance, it works like this: On your first try, you have a 94.4% chance of failing. (this time we use the chance of failing, not the chance of succeeding) On your second try you get a (94.4%)^2 = 89% chance of failing. On your third try you get a (94.4%)^3 = 84% chance of failing. The chance of failing goes down the more often you fail until it eventually approaches (but never reaches) zero. So you always have a small chance of failing and it never gets completely predictable, but the chance of failing over and over again at some point becomes vanishingly small.
So without further ado here is the code:
inline int round_positive_float(float f)
{
return static_cast〈int〉(f + 0.5f);
}
class ControlledRandom
{
float state = 1.0f;
int index = 0;
static constexpr float constant_to_multiply[101] =
{
1.0f,
0.999842823f, 0.999372184f, 0.99858737f, 0.997489989f, 0.996079504f, // 5%
0.994353354f, 0.992320299f, 0.989976823f, 0.987323165f, 0.984358072f, // 10%
0.98108995f, 0.977510273f, 0.973632514f, 0.969447076f, 0.964966297f, // 15%
0.960183799f, 0.955135703f, 0.949759007f, 0.94411546f, 0.93817538f, // 20%
0.931944132f, 0.925439596f, 0.918646991f, 0.91158092f, 0.904245615f, // 25%
0.896643937f, 0.888772905f, 0.880638301f, 0.872264326f, 0.863632858f, // 30%
0.854712844f, 0.845594227f, 0.836190343f, 0.826578021f, 0.816753447f, // 35%
0.806658566f, 0.796402514f, 0.785905063f, 0.775190175f, 0.764275074f, // 40%
0.753200769f, 0.741862416f, 0.730398834f, 0.71871227f, 0.706894219f, // 45%
0.694856822f, 0.68264246f, 0.670327544f, 0.657848954f, 0.645235062f, // 50%
0.6324597f, 0.619563162f, 0.606526911f, 0.593426645f, 0.580169916f, // 55%
0.566839218f, 0.553292334f, 0.539853752f, 0.526208699f, 0.512536764f, // 60%
0.498813927f, 0.485045046f, 0.471181333f, 0.457302243f, 0.443413943f, // 65%
0.429503262f, 0.415506482f, 0.401567012f, 0.38765198f, 0.373695225f, // 70%
0.359745115f, 0.345868856f, 0.331981093f, 0.31815201f, 0.304365695f, // 75%
0.290644556f, 0.277024776f, 0.263462812f, 0.249986023f, 0.236542806f, // 80%
0.223382816f, 0.210130796f, 0.197115764f, 0.184175551f, 0.171426639f, // 85%
0.158810839f, 0.146292359f, 0.133954003f, 0.121768393f, 0.109754287f, // 90%
0.0979399607f, 0.0863209665f, 0.0748278722f, 0.0635780841f, 0.0524956733f, // 95%
0.0415893458f, 0.0308760721f, 0.0203953665f, 0.0100950971f, //99%
-1.0f,
};
public:
explicit ControlledRandom(float odds)
{
if (odds ≤ 0.0f)
index = 0;
else if (odds ≥ 1.0f)
index = 100;
else
index = std::min(std::max(round_positive_float(odds * 100.0f), 1), 99);
}
template〈typename Randomness〉
bool random_success(Randomness & randomness)
{
state *= constant_to_multiply[index];
if (std::uniform_real_distribution〈float〉()(randomness) ≤ state)
return false;
state = 1.0f;
return true;
}
};
(the license for all code in this blog post is the boost license, see text at the bottom. Also, while you’re free to copy+paste this code, note that I had to replace some of the characters with unicode characters because wordpress was being annoying about the “less than” and “greater than” sign, thinking they’re HTML tags. So you have to redo the comparisons and template brackets)
You need to construct one of these ControlledRandom objects for each situation that you don’t want to interfere with other situations. Meaning if you have multiple characters that each have a chance for a critical attack, you need to create one of these objects for each character. The randomness argument is a random engine, for example std::mt19937_64. This one can be shared across instances.
In this function I use a lookup table to determine how much I need to multiply the state variable each time that the function returns fail. You can see that for 19% it is pretty close to the 94.4% number that I mentioned above. Since my lookup table only contains 99 numbers, your probability gets rounded to the nearest multiple of 1%. Meaning if you want a chance of 5.4%, you actually just get 5%. If you want a chance of 0.1%, you actually get a chance of 1%. If you think that that is not OK, keep reading. The solution that I present for the “multiple choices” case will also do things correctly for two choices, and it will do so more precisely.
To convince ourselves that this solves the originally stated problem, let’s go through the case where an enemy is supposed to drop an item 50% of the time. Looking at the table in the code, we find that a 50% chance uses a multiplier of 64.5%. Meaning the first time that you kill the enemy, the item actually only has a 35.5% chance of dropping. But if it doesn’t drop, then you have a 1-64.5%^2 = 58.4% chance the next time. If it still doesn’t drop you get a 73.2% chance, then a 82.7% chance, then a 88.9% chance, 92.8% chance etc. The chance for an item not dropping ten times in a row is now less than 1/10,000,000,000. Before it was 1/1024 Once it does drop, the chance goes back down to 35.5%. Meaning it is less likely to drop twice in a row. The case where you had a 90% chance and missed three times in a row now has a chance of roughly 1/1,000,000, where before it had a chance of 1/1000. A one in a million chance might still be pretty common, but the chance of failing four times in a row is less than 1/1,000,000,000. (and it keeps on decreasing faster and faster. The chance of failing five times in a row is less than 1/100,000,000,000,000)
Controlled Randomness for Multiple Choices
There is a related problem of controlled randomness when you have multiple choices. An example is that you want to populate a highway with traffic and place a bunch of random cars on the road. If you have 10 different types of cars in your game, and you choose completely randomly, you will sometimes get clusters of the same car over and over again. Or you might not see one type of car for a very long time. These are the same kinds of bad cases that we had above. In addition you probably want to also be able to give different cars different likelihoods. For example maybe don’t spawn sports cars as often as SUVs.
Another example of this “multiple choices” controlled randomness is if an enemy has multiple attack patterns and you want him to do a “random” attack each time. This is again an example of emulating a complex system. We don’t want to program the entire decision making logic of the enemy, so randomness is a good substitute. But true randomness can easily lead to repeated identical attacks.
And maybe the most famous example is if your music player is trying to play random music. You don’t want it to play the same two songs over and over again, but that might happen with true randomness.
The classic approach for this is that instead of picking a random song from scratch every time that you decide which song to play next, you instead put all your songs in a list and shuffle the list. Then you walk through it in order. When you get to the end, shuffle it again and start over. You can get a bit fancier to make sure that you don’t get repetition after shuffling, but generally this works well.
The problem with this approach happens when your items are supposed to have a different weight. Like the example of sports cars not showing up on a road as often as SUVs. An easy solution is to just add more SUVs to the list than you add sports cars, but this only works if you want certain fixed ratios between different objects. (like spawning twice as many SUVs as sports cars) The more different categories and different weights you have, the more complicated this problem gets. If you have fifty different cars, all with different weights, you can only do this approximately.
The other day I was running into this problem at work and was thinking about how to solve it properly once and for all, when Jason Frank (engine programmer on Just Cause 4) walked by. Together we came up with a solution that solves this with O(n) memory usage where n is the number of choices, and O(log n) CPU cost. And it allows you to decide if you want to be more random or more deterministic.
The idea is similar to the shuffled list of items. But instead we randomly put the objects on a line. Then we walk along the line and pick up the items in the order in which they were placed. But unlike the shuffled list, we don’t wait until we get to the end. Instead every time that we pick up an item, we immediately place it back on the line a little further ahead. And the distance that we place it is determined by its weight. If object A is supposed to come up twice as often as object B, then we place object A half as far along the line as object B. We also do some randomization so that the objects don’t always come in the same order.
Lets run through this with some numbers. Let’s say we three items: A is twice as common as B, which in turn is three times as common as C. To get this distribution we place C up to 0.6 units further along the line, B up to 0.2 units further along the line and A up to 0.1 units further along the line. Let’s say we are currently at position 0 and in front of us we find object A at 0.05 units, object B at 0.1 units and object C at 0.15 units.
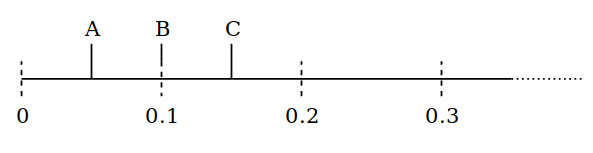
When we pick up the A we roll a random number from 0 to 0.1 and place A that much further along the line. Let’s say we roll a 0.07 and place it at 0.12.

Now the new first object is B because it’s at 0.1. To move that further along the line we pick a random number to add from 0 to 0.2, and lets say we roll 0.11 and end up at 0.21, then A is the first object again.
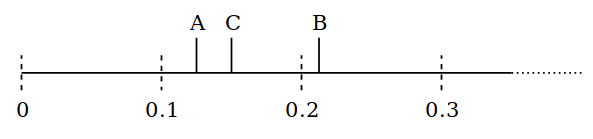
We pick A up again and move it to a randomly chosen position, say 0.17. Then C is the first item.
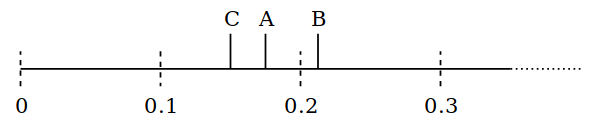
We’re always moving forward and so we’re guaranteed to get to each item at some point, no matter how far along the line it is. Long gaps are less likely than they are with pure randomness. Also repetition is less likely than with pure randomness. I will convince you of that properly later, but for now lets look at the code for this:
class WeightedDistribution
{
static constexpr float fixed_point_multiplier = 1024.0f * 1024.0f;
struct Weight
{
Weight(float frequency, size_t original_index)
: average_time_between_events(static_cast〈uint32_t〉(frequency * fixed_point_multiplier + 0.5f))
, original_index(original_index)
{
next_event_time = average_time_between_events;
}
uint32_t next_event_time;
uint32_t average_time_between_events;
size_t original_index;
};
struct CompareByNextTime
{
uint32_t reference_point = 0;
bool operator()(const Weight & l, const Weight & r) const
{
return (l.next_event_time - reference_point) 〉 (r.next_event_time - reference_point);
}
};
std::vector weights;
public:
WeightedDistribution()
{
}
WeightedDistribution(std::initializer_list〈float〉 il)
{
weights.reserve(il.size());
for (float w : il)
add_weight(w);
}
static constexpr float min_weight = 1.0f / 1024.0f;
static constexpr float max_weight = 10240.0f;
void add_weight(float w)
{
// since I'm using fixed point math, I only support a certain range
assert(w ≥ min_weight);
assert(w ≤ max_weight);
weights.emplace_back(1.0f / w, weights.size());
}
size_t num_weights() const
{
return weights.size();
}
// you need to call this once after adding all the weights to this WeightedDistribution
// otherwise the first couple of picks will always be deterministic.
template〈typename Random〉
void initialize_randomness(Random & randomness)
{
for (Weight & w : weights)
{
w.next_event_time = std::uniform_int_distribution〈uint32_t〉(0, w.average_time_between_events)(randomness);
}
std::make_heap(weights.begin(), weights.end(), CompareByNextTime{0});
}
// use this to pick a random item. it will give the distribution that you asked for
// but try to not repeat the same item too often, or to let too much time pass
// since an item was picked before it gets picked again.
template〈typename Random〉
size_t pick_random(Random & randomness)
{
Weight & picked = weights.front();
size_t result = picked.original_index;
uint32_t reference_point = picked.next_event_time;
picked.next_event_time += std::uniform_int_distribution〈uint32_t〉(0, picked.average_time_between_events)(randomness);
heap_top_updated(weights.begin(), weights.end(), CompareByNextTime{reference_point});
return result;
}
};
template〈typename It, typename Compare〉
void heap_top_updated(It begin, It end, Compare && compare)
{
using std::swap;
std::ptrdiff_t num_items = end - begin;
for (std::ptrdiff_t current = 0;;)
{
std::ptrdiff_t child_to_update = current * 2 + 1;
if (child_to_update ≥ num_items)
break;
std::ptrdiff_t second_child = child_to_update + 1;
if (second_child 〈 num_items && compare(begin[child_to_update], begin[second_child]))
child_to_update = second_child;
if (!compare(begin[current], begin[child_to_update]))
break;
swap(begin[current], begin[child_to_update]);
current = child_to_update;
}
}
The code is a bit more involved, and the heap_top_updated function at the bottom is not strictly needed (it is an optimization of the case where you do std::pop_heap immediately followed by std::push_heap) but lets just go through it step by step with an example:
std::mt19937_64 randomness(5);
WeightedDistribution distribution = { 1.0f, 2.0f, 3.0f, 4.0f };
distribution.initialize_randomness(randomness);
std::vector〈size_t〉 num_picks(distribution.num_weights());
for (int i = 0; i 〈 10000; ++i)
{
++num_picks[distribution.pick_random(randomness)];
}
In this example I create a weighted distribution with the four weights 1, 2, 3 and 4. Meaning the fourth item will be picked four times as often as the first item. After adding the weights I have to call initialize_randomness once, otherwise the first couple picks will be deterministic. Then I just call pick_random in a loop and count how often each item gets picked. In this case the first item gets picked roughly 1000 times, the second one roughly 2000 times, the third one roughly 3000 times and the last one roughly 4000 times.
To understand the code, the first thing I need to explain is why I use fixed point fractional numbers instead of floating point numbers. The reason is that an infinite line is easier to represent when using uint32_t than when using floats. Floats lose precision once the numbers get too big, and you have to do some work to fight that. Like by shifting the whole line back every once in a while. But uint32_t has no such problem. It will increment and wrap around forever without any problems. The only thing I had to do was be a bit clever in CompareByNextTime to handle the case when a uint32_t wraps around. Otherwise the code doesn’t really depend on this being fixed point math. The conversion happens when a weight is first added and this isn’t an issue anywhere else.
So lets go through the code. In initialize_randomness I assign each item a position along the line, randomly chosen from 0 to the furthest distance it can be placed. Then I turn that into a min-heap so that the item with the lowest distance will be first on the heap. With that lets move on to pick_random.
First I pick the first item in the list which will have the lowest next_event_time. I then assign it a new position in the list by incrementing its next_event_time by a randomly chosen number and then update the heap to move this item back on the line. The reference_point is a trick to handle the case when the uint32_t wraps around.
The important part is in how I choose to increment its next_event_time: In this code I just increment it with a number from 0 to the average time between events. This number will be different for each weight. In the above example it will be 1 for the first weight, 0.5 for the second weight, 1/3 for the third one and 0.25 for the last one. (except using fixed point math, so 1024*1024 for the first one and 256*1024 for the last one) Meaning the last one gets placed up to 0.25 units further along the line, and the first one gets placed up to 1 unit further along the line. Just from that it should be clear that the last item gets picked four times as often.
So incrementing the number means pushing an item further back on the line, and updating the heap means walking along the line.
But does this actually give us controlled randomness? Where is the guarantee that this doesn’t behave just as randomly as if we pick a random item from scratch each time? Because in theory we could randomly get very small numbers many times in a row, and only move along the line very slowly. The easiest way to verify that this works as intended is to simulate the behavior over a long time. Say a million random picks. Then we count how big the gaps between two picks were, and how often an item got picked twice in a row. For the purposes of this I’m going to look at the third item from my above example, which should get picked 3/10 times over the long term. If I use true randomness to always pick a random item according to the weights, I get the following distribution of wait times between picks:
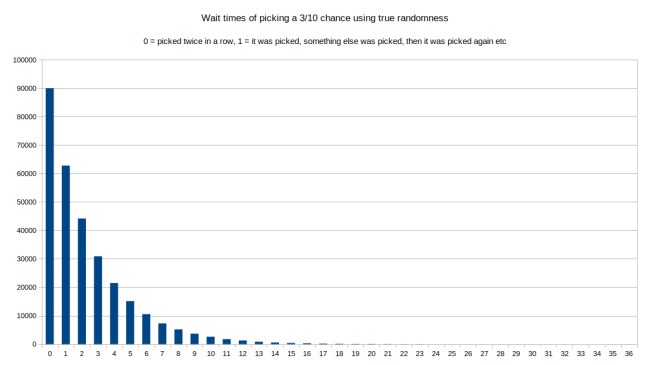
In this one we can see that over a million runs, the most common choice (90000 times) was that item three was picked twice in a row. It was also pretty common that it was picked with just one other item inbetween. The longer the gap between choices, the less likely. But look at the right tail: The longest gap between being chosen was a wait time of 36 items. Meaning choice number 3 was picked, then 36 other items were picked before choice number 3 was picked again. Lets try the same thing with controlled randomness:
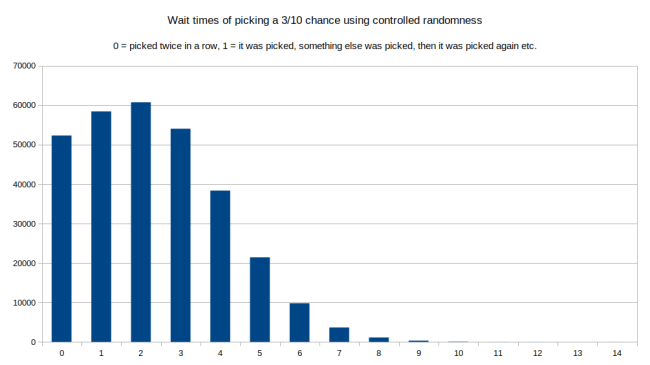
Here we see that being picked twice in a row is actually not that common any more. Instead a wait time of 2 is the most common. And the tail at the end is far shorter. The longest wait time was 14. And this was far less common than when we tried this with true randomness.
The interesting part about this algorithm is that we can mess with how we move items along the line. For this example I just used a uniform_int_distribution from 0 to the average wait time. If we use a std::exponential_distribution(1 / average_wait_time) instead, (taking care to convert from fixed point math back to floating point math) we would look a lot like the first picture. Because the exponential_distribution is defined to be exactly the first picture. The definition on Wikipedia says: The exponential distribution is the probability distribution of the time between events in a process in which events occur continuously and independently at a constant average rate. So lets try it:
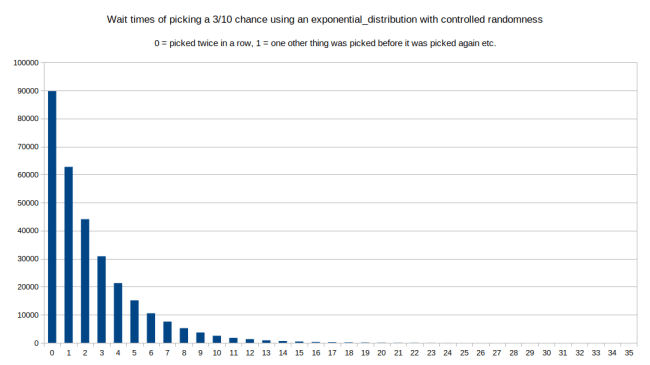
This looks pretty much exactly like the first picture. In this case the longest wait time was 35 instead of 36, but that’s just random noise.
What happens if we use no randomness at all and just always add the average_time_between_events?
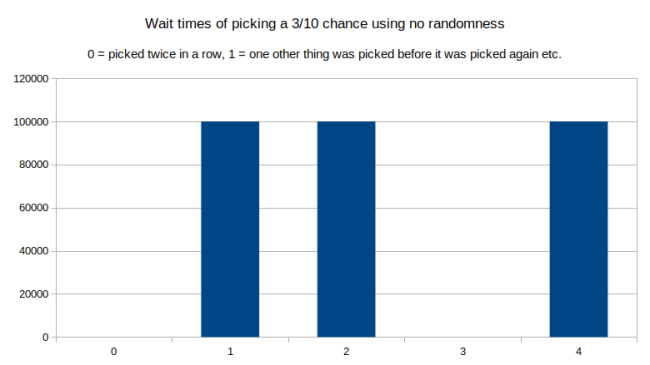
Isn’t that interesting? If we remove all randomness, it never gets picked twice in a row, and it never has a wait time of 3. There is always one or two or four other items picked before it gets a chance to get picked again. This makes sense once you think about it: Without randomness you fall into a repeated pattern as you walk along the line.
But finally this is the point where we get to control how much randomness we want in this: We can use any blend of any of the above methods. As long as we always have the same average distance between points on the line, we are not going to disturb the long-term distribution of the values. So for example here is what I get when I use 75% controlled randomness (the graph with the highest wait time of 14) and 25% no randomness (the last graph):

This is really cool: The chance of being picked twice in a row went down, and the length of the tail also went down. The longest wait time is now 7. But it will still get picked 3/10 times on average. So using this approach of mixing different distributions, we can exactly control how much randomness we want and how much we want to control things. In fact we can freely mix and match per item. Maybe if an item is really important we want it to drop at a certain fixed rate. But if something is less important we are fine with it behaving more randomly. As long as we don’t mess with the averages we can do any mix we want.
There is a second problem that we can look at: How long is the longest chain of picking the same item before something else was picked. Let’s look at the same item from the above example, the one that should be chosen 3 out of 10 times on average. Using true randomness here is the distribution of how often it was picked in a row when it was picked:
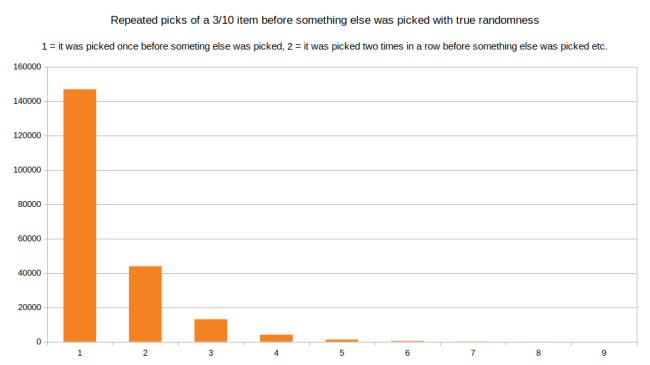
Here we can see that by far the most common case is that it was picked once before something else was picked. But being picked two times in a row or three times in a row is not that uncommon either. And the longest chain was that it was picked nine times in a row before something else was chosen. Now lets look at what controlled randomness does to this distribution:

It looks somewhat similar to before, but it’s actually more skewed towards the number 1. Meaning the item was just picked once before something else was picked. We can compare the height for number 2 just by reading the labels, but the change gets bigger the further we move along: There were 4087 cases where the item was chosen four times in a row when using true randomness. At the same number of attempts there were only 769 cases where it was chosen four times in a row using controlled randomness. Meaning the longer the chain, the bigger the difference in likelihood. Controlled randomness makes alteration more likely and makes it less likely to pick the same thing repeatedly. And finally we can see that the longest chain is now 7.
If we do a mix of controlled randomness and fully deterministic, the difference is even more striking. Here is the mix of 75% controlled randomness and 25% deterministic: (deterministic meaning we don’t add a random number, but just add the average_time_between_events)
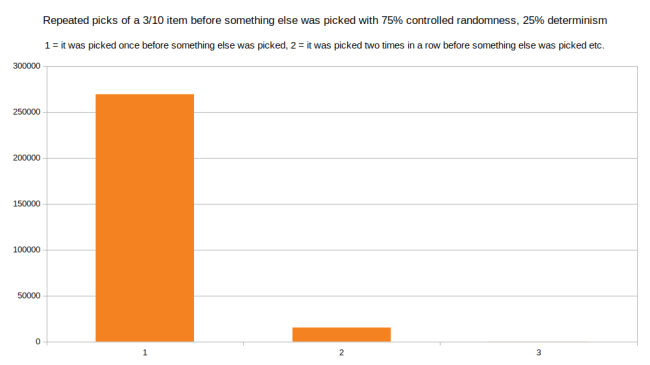
Just mixing in 25% determinism makes long chains go away entirely. The longest chain is now that the item was picked three times in a row. This makes sense because the determinism adds a minimum step size to our steps along the line. And you can only step so far before you’re guaranteed to run into something else.
I think with this the problem of controlled randomness is solved. Lets go through all the problems that we talked about and see if they are solved:
- We want to avoid picking the same thing too often in a row: Solved because the chance of picking the same thing multiple times is lower than it is with true randomness. And if we mix in some determinism it gets even lower.
- We want to avoid having to wait a very long time until something finally succeeds: Solved because the tail end of the wait time distributions above is much shorter.
- We want to avoid being too predictable. This was a problem with the Warcraft 3 model of controlled randomness: Anything above 70% could only ever fail once in a row. If it failed once you were guaranteed that it would succeed the next time. This does not happen with this new algorithm for controlled randomness (except if you mix in too much determinism)
- We want to avoid that certain items are never picked in certain situations. I didn’t mention this before, but this is a problem with the first algorithm for controlled randomness in both the Warcraft 3 version and in my version based on multiplication: To get a 1% chance in the long term you have to start off with a chance of just over 1/10,000 on the first try, and then slowly ramp up the chance. Meaning if something has a 1% chance, you are almost certain to never get lucky and get it on the first try. This new algorithm of controlled randomness does not have this problem. It’s no more unlikely to get a 1% chance on the first try than it is with true randomness.
- We don’t want to mess with the distribution. The Warcraft III solution actually only gave a 60% success chance when a designer asked for a 70% success chance. We don’t want that. It’s fine to make the randomness feel closer to what people expect, but it’s not fine to deceive our own designers when they tweak the numbers. That’s just super confusing.
Another bonus point is that this is efficient: O(n) storage space with n being the number of items, and O(log n) CPU time to pick the next item. This means that this is fast enough to play a random song from your entire music collection, but of course it can also be used for small numbers, like to pick one of three random attacks. You can also use this to replace the first algorithm for the success/fail case only. If you do, you can refactor it to not use a std::vector internally and to not use a heap and to not use fixed point numbers. It’s a fun exercise to simplify it down far enough, so I’ll leave that as an exercise to the reader. I don’t think that you can bring it down to a single float state variable like in the first code that I posted, but doing it with two floats is possible.
Here is a link to the code on github.
Also at the end is a link to a great blog post about randomness if you want to know more about how to use randomness responsibly in other cases:
https://eev.ee/blog/2018/01/02/random-with-care/
Oh and here is the license text for all the code above. If you just want to refer to the algorithm don’t say “it’s an algorithm invented by Malte Skarupke” instead say “it’s an algorithm invented by Jason Frank and Malte Skarupke” because Jason Frank had the crucial idea of placing objects on a line and the insight that you can control the randomness. I just wrote the code. Anyway the license:
// Copyright Malte Skarupke 2019. // Distributed under the Boost Software License, Version 1.0. // (See http://www.boost.org/LICENSE_1_0.txt)
And once again the github link as the last thing for the people who just scrolled to the end to find the link.

I think you will find “Quasirandom Ramblings” by Brian Hayes in American Scientist an interesting read:
https://www.americanscientist.org/article/quasirandom-ramblings
He makes an interesting observation on randomness:
“ The concept of randomness in a set of numbers has at least three components. First, randomly chosen numbers are unpredictable: There is no fixed rule governing their selection. Second, the numbers are independent, or uncorrelated: Knowing one number will not help you guess another. Finally, random numbers are unbiased, or uniformly distributed: No matter how you slice up the space of possible values, each region can expect to get its fair share.”
Hi,
This is a very interesting article. I have two things to say.
First, I think it is possible to bring the binary case down to a state of a single float, with a second float for some kind of “reset” like in your first code. I haven’t implemented it yet, but here is the idea:
The state would represent the distance between the two events on the line. When a sample is drawn, the pseudo-code would be like this:
if state is positive:
state -= random between 0.0 and 1.0
return 1
else: (state is negative)
state += random between 0.0 and frequency_ratio
return 0
where frequency_ratio is for example 10.0 if the positive event occurs 10 times more often than the negative one.
Second, I think that the way used to initialize the randomness makes the few first draws a bit biased in favor of frequent events.
The intuitive explanation that I came up with is the following, the method initialize_randomness is like if all events were at position 0.0 and got drawn once (and got discarded). The controlled randomness, that makes unlikely events even more unlikely to occur after they have been drawn, will play here too, and makes unlikely events more unlikely after initialization.
With a concrete case, it is possible to show it more formally. Let’s take the binary case with a likely event, A, that takes steps of size up to 1.0, and an unlikely one, B, with size up to 10.0. If the initialization is unbiased, A and B have probability to occur of 10/11 and 1/11. But if we draw their initial position like in initialize_randomness and take the smallest one, we don’t get these probabilities. The initial position of B has 1/10 chance to be smaller that 1.0, and in that case it has 1/2 chance to be smaller than A. Thus B has 1/20 chance to have the smallest position just after initialization.
This is close to be half as likely as it should be. In the binary case, it looks like very unlikely events become nearly twice as unlikely as they should after initialization. This is far better than what you reported from the Warcraft engine (0.01 becoming ~0.0001, while here that would be ~0.005) which is nice.
It seems that in cases with n events where one is much less likely than the others, the initial probability of the unlikely one gets close to be divided by n.
I haven’t found a smart and better way to initialize the positions. Best I can suggest is to initialize like in initialize_randomness then draw a few more samples (and discard them). I don’t know what would be a good number for “a few more”, the goal of this idea is to avoid depending on the initial draw of the unlikely events.
Thanks, great comment.
The code for doing this kind of randomness with just one float for the state variable was almost right. I tried it and while at first it didn’t work, it is the right idea. (I especially like the trick of using the sign of the float to switch between the two states) The working pseudo code is this:
if state is positive:
state -= random between 0.0 and (1.0 / (1.0 – chance))
return false
else: (state is negative)
state += random between 0.0 and (1.0 / chance)
return true
With that it works while just keeping a single variable for the state.
About the first couple samples being wrong: That’s is a good point, and there should be a better algorithm than just taking a few samples to initialize things properly.
I don’t know how to solve it properly, so I thought maybe let’s just try to find out how many samples are “enough”. One thought was to change what initialize_randomness does. Instead of assigning next_weight for all the variables, it would instead just call pick_random() in a loop until the value with the lowest weight has been picked once. At that point we’re guaranteed to have seen each value once. And then, if it has taken n samples to get to that point, do another 0.5n samples because otherwise we’re guaranteed to not see that last value for a while.
That’s definitely going to be better, but not I’m not sure by how much. (it also would take a while if you run this on your entire music collection) Unfortunately my statistics knowledge isn’t good enough to solve this properly.
Hi,
I found a way to initialise randomly the positions in a way that avoids any bias!
First, select the first item according to true randomness. Its position in the list is set to 0.
Then, for each other item, set its position according to a distribution that linearly decreases between 0 and its step size.
This is basically black magic. In my experiments, it just seems to work well: samples for each of the first few draws have the same ratio (with some noisy error) as the ones that come later.
The idea of a linearly decreasing distribution came to me when I tried to find the distribution of position an item just after it passes another one (the actual distribution depends on the distribution just before passing, it is a linearly decreasing distribution if it was uniform before). But I don’t have a justification for why it works.
To sample a linearly decreasing distribution between 0 and w, I found 2 possibilities:
1 – sqrt(1 – uniform(0,w))
abs(uniform(0,w) – uniform(0,w))
depending on whether you prefer computing a square root or using a second random value.