A new fast hash table in response to Google’s new fast hash table
by Malte Skarupke
Hi, I wrote my new favorite hash table. This came about because last year I wrote the fastest hash table (I still make that claim) and this year one of the organizers of the C++Now conference asked me to give a talk. My problem was that Google had also announced a new fast hash table last year, and I wasn’t sure if mine would compare well against theirs.
The main benefit of Google’s hash table over mine was that Google’s has less memory overhead: It has a higher max_load_factor (meaning how full can the table get before it grows to a bigger array) and it has only 1 byte overhead per entry, where the overhead of my table depended on the alignment of your data. (if your data is 8 byte aligned, you’ll have 8 bytes overhead)
So I spent months working on that conference talk, trying to find something that would be a good response to Google’s hash table. Surprisingly enough I ended up with a chaining hash table that is almost as fast as my hash table from last year, while having even less memory overhead than Google’s hash table and which has this really nice property of having stable performance: Every hash table has some performance pitfalls, but this one has fewer than most and will cause problems less often than others will. So what that does is that it’s a hash table that’s really easy to recommend.
Stable Performance
The main trick of my fastest hash table was that it relied on this upper bound for the number of lookups. That allowed me to write a really tight inner loop. However when I brought that into work and told other people to use it, I quickly ran into a problem: When people gave the hash table a bad hash function, the hash table would often hit the upper bound and would often have to re-allocate, wasting lots of memory.
Writing a good hash function is a really, really tricky undertaking. It actually depends on the specific hash table that you’re writing for. For example if you want to write a hash function for a std::pair<int,int>, then you would probably want to write a different hash function for std::unordered_map than you would use for ska::flat_hash_map, and that one would be different from what you would use for google::dense_hash_map which again would be different from google::flat_hash_map. You could come up with one hash function that works for everything, but it would be unnecessarily slow. The easiest hash function to write for std::pair<int,int> would probably be this:
size_t hash_pair(const std::pair〈int, int〉 & v)
{
return (size_t(uint32_t(v.first)) << 32)
| size_t(uint32_t(v.second));
}
So since we have two 32 bit ints, and have to return one 64 bit int, we just put the first int in the upper 32 bits of the result, and the second int in the lower 32 bits of the result.
Having just done a huge investigation into hash tables for my talk about hash tables, here's what I would tell you about this hash function: It would work great for the GCC version and the Clang version of std::unordered_map, it would work terribly for the Visual Studio version of std::unordered_map, it would cause ska::flat_hash_map to re-allocate unnecessarily, but not by much, and it would be terrible for google::dense_hash_map.
What's wrong with it? A few things: Half the information is in the upper 32 bits. The Visual Studio implementation of std::unordered_map and google::dense_hash_map use a power of two size for the hash table, meaning they chop off the upper bits. So you just lost half of your information. Oops. ska::flat_hash_map however would run into problems if the v.second member has sequential integers in it. Meaning for example if it just counts up from 0. In that case you get long sequential runs, which can sometimes cause problems in ska::flat_hash_map. (usually they don't, but sometimes they do and then the table will re-allocate a lot and waste memory)
The best way to fix this properly is to use a real hash function. FNV-1 is an easy choice to use here and it would make the hash work well for all hash tables. Except that you using FNV-1 will make all your find() calls more than twice as slow because a real hash function takes time to finish…
So writing a good hash function is really tricky and it's probably the easiest way to mess up your performance. When I said that my new hash table has stable performance, among other things I meant that it's robust against hash functions like this one. As long as your hash function isn't discarding bits, it'll probably be OK for my hash table.
bytell_hash_map
The table is called ska::bytell_hash_map, and it’s a chaining hash table. But it’s a chaining hash table in a flat array. Which means it has all the same memory benefits of open addressing hash tables: Few cache misses and no need to do an allocation on every insert. Turns out if you’re really careful about your memory, chaining hash tables can be really fast.
The name “bytell” stands for “byte linked list” which comes from the idea that I implemented a linked list with only 1 byte overhead per entry. So instead of using full pointers to create a linked list, I’m using 1 byte offsets to indicate jumps.
I won’t go into more detail here, mainly because I’m a little bit burned out on this hash table right now. I just spent literally months working on hash tables for this conference talk, and a good blog post about this would take me more months. (my blog post about the fastest hash table last year definitely took more than a month of free time) So what I’ll do is I’ll link to the talk once it’s online (the first C++Now talks were uploaded last week, so it shouldn’t be too long for the talk to be available) and otherwise keep the blog post short.
So for now here are two graphs that show the performance of this hash table. First for successful lookups (meaning looking up an item that’s in the table):

This is the graph for a benchmark that’s spinning in a loop, looking up random items in the table. On the left side of the graph the table is small and fits in cache, on the right side the table is large and doesn’t fit in cache. In this graph we mostly just see that std::unordered_map is slow (this is the GCC version of std::unordered_map) so let me remove that:
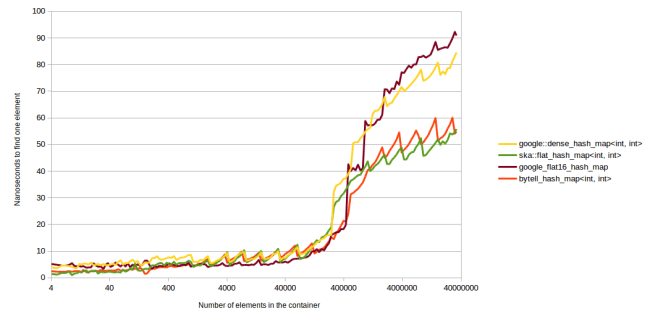
This one I’ll talk about a little bit. The hash tables I’m comparing here are google::dense_hash_map, ska::flat_hash_map (my fastest table from last year), bytell_hash_map (my new one from this blog post) and google_flat16_hash_map. This last one is my implementation of Google’s new hash table. Google hasn’t open-sourced their hash table yet, so I had to implement their hash table myself. I’m 95% sure that I got their performance right.
The main thing I want to point out is that my new hash table is almost as fast as ska::flat_hash_map. But this new hash table uses far less memory: It has only 1 byte overhead per entry (ska::flat_hash_map has 4 byte overhead because ints are 4 byte aligned) and it has a max_load_factor of 0.9375, where ska::flat_hash_map has a max_load_factor of 0.5. Meaning ska::flat_hash_map re-allocates when it’s half full, and the new hash table only reallocates when it’s almost full. So we get nearly the same performance while using less memory.
Here we can also see the second thing that I meant with more stable performance: This new hash table is much more robust to higher max load factors. If I had cranked up the max_load_factor of flat_hash_map this high, it would be running much slower. So stable performance leads to memory savings because we can let the table get more full before it has to grow the internal array.
Otherwise I’d just like to point out that this new table easily beats Google’s hash tables both on the left, when the table is in cache and instructions matter, and on the right when cache performance matters.
The second graph I’m going to show you is for unsuccessful lookups. This time I’m going to skip the step of showing you unordered_map:
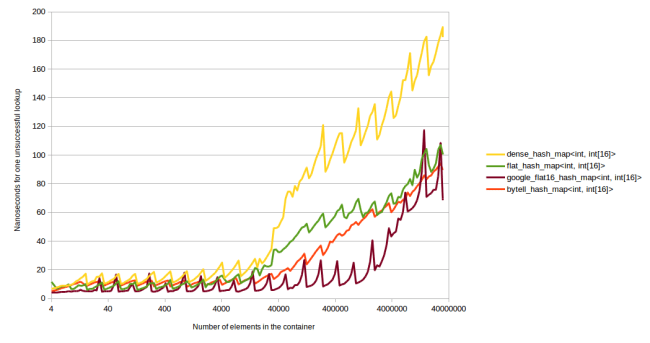
In unsuccessful lookups (looking up an item that’s not in the container) we see that Google’s new hash table really shines. My new hash table also does pretty well here, beating ska::flat_hash_map. It doesn’t do as well as Google’s. That’s probably OK though, for two reasons: 1. This hash table does well in both benchmarks, even if it isn’t the best in either. 2. Google’s hash table actually becomes kinda slow when it’s really full (the spikiness in the graph just before the table re-allocates), so you have to always watch out for that. Bytell_hash_map however has less variation in its performance.
I will end the discussion here because I don’t have the mental energy to do a full discussion like I did last time. I need a rest from this topic after just having spent lots of energy on the talk. But I ran a lot more benchmarks than this, and this thing usually does pretty well. And sometimes all you want is a hash table that’s an easy, safe choice that people can’t mess up too badly which is still really fast.
I’ve added bytell_hash_map to my github repository. Check it out.

Very impressive!
Since this implementation uses chaining, would it be possible to use it as an replacement for std::unordered_multimap? I tested it quickly but it doesn’t seem to work, even though from a glance in the code it seems supported.
Maybe I just had an implementation mistake though.
Regards,
I don’t provide a multimap implementation because I haven’t seen a good use case for an unordered_multimap. In most cases I would just use std::multimap. The problem with unordered_multimap is that you’re intentionally running into the worst case behavior of hash tables: You insert many values that have the same value, so you get many hash collisions. So I would be worried about running into really bad cases, and I’d just use a binary search tree (std::multimap) to get guaranteed upper bounds on performance.
So if you have a real use case, I’d be curious to hear about it.
Thank you for your response!
In my use case I am storing key,value pairs that can have the same key. The key being a uint64_t hash and the value a pointer to a struct. When I process new incoming data I look up if there are any matching hash values (keys) and compare the stored data in the structs with the new struct (no updates of the hashmap, just read at this point). There it is essential to compare all existing entries of this one hash, not only one.
If course I could change this to use some kind of key,std::vector but it is much simpler to use the insert functionality of multimaps. The performance is okay, but the ram usage is exploding and using your implementation would bring it down by about 600MB and is also slightly faster.
Regards,
Could you open-source your implementation of google’s data-structure and the benchmarks, even if it is only in a github gist?
Yes, will do. Give me a week to do it. I’ve been finding it very hard to work on this after I was finished with the talk. I’m just kinda burned out after spending all my free time on this for several months. So my strategy to finish this has been to do small things like this blog post.
This seems to be very nice work, thanks for publishing it. Is there any chance you can open source a current version of your profiling setup?
Yes, I’ll definitely open source it. It has actually grown into a whole UI application where I can benchmark all kinds of combinations of behavior for different hash tables. It requires its own blog post to introduce.
Have you seen the robinhood/hopscotch hashmaps benchmarked here? Their speed seems to compare to google’s as well.
https://tessil.github.io/2016/08/29/benchmark-hopscotch-map.html
What are your thoughts on them?
I did benchmark against them, and I thought that they were really good. I did the benchmarking a while ago, so here is just what I remember from memory:
His robin hood hashing table seems to be pretty much exactly the same speed as mine. It seems slightly faster in some benchmarks, slightly slower in others. It’s always a tiny difference so my conclusion is that it’s just the same speed.
The hopscotch hashing one is also really good. If I remember correctly it’s usually a little bit slower than robin hood hashing on average. Which makes sense because there is more work to be done in Hopscotch hashing in the ideal case. The ideal case being “the first item you look at is immediately the thing you were looking for.” And it just so happens that in any decent hash table, the ideal case is also the most common case. Hopscotch hashing puts more instructions in the path of that ideal case, so it’s usually slightly slower on average. It’s still really fast though. For example I don’t know from memory right now how it compares against my new hash table that I’m presenting in this blog post. I do know though that it’ll have more memory overhead.
I’ll re-run those benchmarks when I got home this evening and I’ll let you know how they compare. But for comparisons of his hashtables against my old one, I think his benchmarks are pretty close to what I found. (at least for all the lookup benchmarks. Since lookups are the most important operations on hash tables, I usually focus on those, so I don’t remember how my benchmarks for the other operations compared)
So I re-ran the benchmarks and his robin hood hashing table is roughly equal to mine, and his hopscotch hashing table is slightly slower than both of the ones shown here. It does well when compared to other tables though.
I only measured lookups.
Thanks for this. It was very interesting and well written.
Have you also benchmarked CCAN’s htable module? It appears to get consistently good scores in most tests, except that it’s a basic single-table system underneath so the maximum add latency gets bigger with number of elements.
I wasn’t familiar with it. Since it has a custom C interface that only supports inserting pointers, it’s not easy to adapt it to my benchmarks. Do you have a link to existing benchmarks?
No. Apparently I, just as other hash table enthusiasts, wind up never showing my exact method for fear of them becoming canonical past the point of irrelevance (like e.g. Dhrystone have before, and the language shootout). However, converting from a “container_of() style” setup to storing K->V pairs only requires an intermediate structure and a hash function for each case, and possibly some lifecycle goo for C++. If V is a pointer, your benchmark will penalize htable in comparison to its usual application.
Since the comment section seems to be accumulating a list of contenders, let me add folly’s F14 hash table ( https://github.com/facebook/folly/blob/master/folly/container/F14Map.h and friends). It has a bit mixing step for integral keys, which handicaps it a bit for microbenchmarks that have uniformly random keys.
I use hash tables a lot, so they need to be fast. I wrote my own hash container years ago which I use in my compression software (it’s not standalone but could be):
https://github.com/BinomialLLC/crunch/blob/master/crnlib/crn_hash_map.h
It uses open addressing, linear probing, it auto resizes on ~50% load factor, and it uses Knuth’s multiplicative method (Fibonacci hashing). It supports the usual things (find/insert/erase) and iterators. I remember spending time optimizing the find method for good code gen on x86. I make no claims it’s fastest, but it’s pretty fast vs. the stdlib’s containers.
Anyhow, I timed the latest version of flat_hash_map.hpp vs. mine just to see where I’m at, for insertions, on x64 using VS2015:
Time to insert 1,000,000 random uint32_t keys (with uint32_t values):
crnlib::hash_map: 0.114513 secs
ska::flat_hash_map: 0.205309 secs
std::unordered_map: 0.301911 secs
Time to insert 100,000 random uint32_t keys:
crnlib::hash_map: 0.010127
ska::flat_hash_map: 0.012289
std::unordered_map: 0.019048
I tried your other hash map, but it performed similarly for this test. I haven’t investigated why, but flat_hash_map seems to have some bottlenecks slowing it down. It could definitely be faster.
Couple more sets of timings:
10K insertions:
0.001114
0.001325
0.001678
10M insertions:
2.315583
3.077449
6.018827
40M insertions:
8.696308
11.965869
32.177230
So in both of my hash tables I accept that inserts are a little bit slower in order to make lookups as fast as possible. It’s just a trade-off that I decided to make. I value lookups more than inserts because I usually do more lookups than I do inserts.
So both of these tables have certain invariants to maintain that I can then take advantage of when doing lookups. ska::flat_hash_map has the robin hood invariants that ensure that every item is as close as possible to its ideal position. For that it has to shuffle items around on insert, slowing insertion down. bytell_hash_map has a bit more complicated invariant that I explained in the talk which should hopefully be online soon.
If you want a hash table with really fast inserts, Google’s new hash table may actually be what you’re looking for. In my benchmarks that one has by far the fastest inserts.
If I remember to do so this evening, I will run my insertion benchmarks as well and add the graph to the blog post.
I did some benchmarking, and I have to say I really like your hash table. It does have really fast inserts. It has the same memory overhead as my flat_hash_map, and for successful lookups it’s actually pretty much as fast. (which I was surprised by) For unsuccessful lookups it’s a bit slower. But for inserts it is indeed much faster.
So your table has slightly different trade-offs than mine, but those may be worth it. If you rarely do unsuccessful lookups, your hash table is probably a better choice than my flat_hash_map. Since bytell_hash_map came out of wanting to save memory, that one has different trade-offs though.
But if you make your hashtable work standalone, I think people would want to use it.
The biggest surprise for me though is Fibonacci hashing. I’m amazed I haven’t heard of it before. It’s a great idea. I may have to change my flat_hash_map to use it by default. So far I’m using some tricks to make integer modulo faster, but Fibonacci hashing has the really nice feature that it spreads out sequential numbers. So you get an additional step of randomization which would be really useful for my flat_hash_map, because certain patterns can really mess it up.
Part of the reason I’m amazed by Fibonacci hashing is that all the big implementations of std::unordered_map (GCC, Clang, Dinkumware/Visual Studio, boost) don’t use it. But they would all be much faster if they used Fibonacci hashing, and as far as I can tell there wouldn’t be any downsides to that. So I’ll look into it a bit more just to make sure that there are no hidden pitfalls, but otherwise it looks like you revived a cool trick from computing history that everybody else seems to have forgotten about.
I cannot find Google’s flat_hash_map! You reference it here as google::flat_hash_map. But I simply cannot find it. I’ve watched Matt K’s talk, but I can’t find this code anywhere. Can you point me at it? Thanks!!
Hi, I haven’t uploaded my version of Google’s flat_hash_map yet. Google has wanted to open source theirs for a while now, and I do still think that they’ll do that at some point soon. My version will also be online soon-ish. I’m just on vacation right now and don’t want to work on programmer things.
But I have been told by others that there are open source versions out there. I never went looking for them myself though, so not sure what it’s called or who did that. It’s just a thing that somebody told me at CppNow, because they were also playing around with Google’s flat_has_map, or rather with a version that somebody uploaded.
Hi Malte. I have readed your hash table versions. They are excellent. I watched Matt’s video in CppCon 2017. I am very curious about how to install google::flat_hash_map but i don’t still find open source in github. Can you point me at it? Thanks!!
You started by describing the importance of hash functions to the performance of hash tables. If I recall correctly, in the CppCon presentation, they did not tell anything about the hash function they use.
Which hash function are you using to do the comparison between the hash tables? Could the performance difference in the benchmark be affected by the hash function choice?
I’m saying that because I too implemented the hash table they describe in the CppCon presentation, but then I went to spend a few weeks trying out hash functions just to realize that topic can be more complex than the hash table itself.
Hi Malte,
first of all thanks for not only posting your hash tables but also for discussing and explaining them in detail.
We are currently evaluating several hash tables in our research database Hyrise. One operation uses radix clustering to partition data in way that each hash table fits into the L2 cache.
Currently, we are struggling trying to estimate the memory consumption of the bytell hash table. We know the number of elements, the data type and so on. Is there a rule of thumb for the size of your hash maps?
Best
Martin
Bytell should have exactly 1 byte overhead per entry. So the exact memory usage should be something like (size() * (sizeof(T) + 1)) / load_factor().
So to run through an example, let’s say
one key/value pair in the map is 16 bytes in size,
there are 48 items currently in the map,
and the load_factor is 0.75.
Meaning the table is 75% full and the internal allocation has enough space for 64 items. The map will add one byte overhead, to arrive at 17 bytes per entry. So in this case memory usage would be (48*(16 + 1))/0.75 = 1088.
That should be the size of the heap allocation. There will be some more memory for the map itself. I’m not sure exactly how much right now, but it should be less than 100 bytes. You can find out by just taking sizeof(ska::bytell_hash_map) with your key and value pair. Also note that the table will re-allocate before it’s 100% full. By default it re-allocates when it’s 93% full. It does this because when the table gets too full, performance suffers. And sometimes it has to re-allocate before that if there are too many hash collisions. That should be rare, but it might be a problem if your performance depends on the table not resizing to be bigger than the L2 cache. Just keep an eye out for how often this happens to you.
Oh and for my other hash table, flat_hash_map, the memory usage should be (size() * (sizeof(T) + alignof(T)) / load_factor(). That one only has a max_load_factor() of 0.5 by default, so it re-allocates when it’s only half full. You can increase that, but the table does get slower when you do. Increasing it to 0.75 should still be OK, but 0.9 might be too high. Once you get past a certain load_factor, things get very slow very quickly. I picked 0.5 by default because that gives stable performance: There isn’t too much of a difference between a table that’s just about to re-allocate and a table that’s almost empty. At 0.75 there will be more of a difference, at 0.9 there will be a big difference between an empty table and a table that’s about to re-allocate.
Very interesting posts! I would be particularly interested in a “plain C” version of your hash-table… have you got such a creature?
I do not. I’m not fluent enough in C to know what a hash table would look like. I can read C, but I don’t know what people would expect from a hash table. Surely you would want to allow customization, but I can’t imagine how to do that without templates.
Yes, well, I already wrote a version suited to my needs. You can read about my travails here: https://8th-dev.com/forum/index.php/topic,1736.msg9653.html
Malte,
I’d love to see an update to this article, now that Google’s implementation is released.
https://github.com/abseil/abseil-cpp/tree/master/absl/container
You might be interested in my research on cuckoo hashing:
https://github.com/alainesp/Practical_Research/blob/master/research_cuckoo_cbg.md
I’ll check it out later this week, thanks!
What’s google new hash table ? I only know dense_hash_map and sparse_hash_map,anything else?Does google release it?
Currently there is a pretty good map comparison repo in github with a blogpost discribing the results. Link is here: https://github.com/martinus/map_benchmark.
It compares basiclly all the popular fast map including your ska::flat/bytell and tossil’s map, google’s and facebook folly’s map.
And your flat map are very close to the fastest one. Maybe there are some new improvements lists there? I am not sure.
maybe you can check it.
Thx.
Saw your talks on hash tables and radix sorting.
Dude! They are brilliant! I’m going to forcefully recommend them in my talk about algorithms in the standard library.
Please, continue to give awesome talks with brilliant insights!
Hope to meet you some day and geek out about optimization and stuff. 🙂
What is the reason behind using a union to store data https://github.com/skarupke/flat_hash_map/blob/master/bytell_hash_map.hpp#L105 ?
Is it because union can not have members as a reference type or is it something else?
It’s so that the data is not initialized in the constructor, and not destroyed in the destructor. I am using placement new and I’m manually calling the destructor at different times. Also I need to support objects that don’t have a default constructor.
If cpu is pinned does this mean it is rarely going out of the L3 cache ? Or can it be pinned and still going to main memory? Basically I’m trying to see if atop is useful for telling us that we are not going to main memory.