Fibonacci Hashing: The Optimization that the World Forgot (or: a Better Alternative to Integer Modulo)
by Malte Skarupke
I recently posted a blog post about a new hash table, and whenever I do something like that, I learn at least one new thing from my comments. In my last comment section Rich Geldreich talks about his hash table which uses “Fibonacci Hashing”, which I hadn’t heard of before. I have worked a lot on hash tables, so I thought I have at least heard of all the big important tricks and techniques, but I also know that there are so many small tweaks and improvements that you can’t possibly know them all. I thought this might be another neat small trick to add to the collection.
Turns out I was wrong. This is a big one. And everyone should be using it. Hash tables should not be prime number sized and they should not use an integer modulo to map hashes into slots. Fibonacci hashing is just better. Yet somehow nobody is using it and lots of big hash tables (including all the big implementations of std::unordered_map) are much slower than they should be because they don’t use Fibonacci Hashing. So let’s figure this out.
First of all how do we find out what this Fibonacci Hashing is? Rich Geldreich called it “Knuth’s multiplicative method,” but before looking it up in The Art of Computer Programming, I tried googling for it. The top result right now is this page which is old, with a copyright from 1997. Fibonacci Hashing is not mentioned on Wikipedia. You will find a few more pages mentioning it, mostly from universities who present this in their “introduction to hash tables” material.
From that I thought it’s one of those techniques that they teach in university, but that nobody ends up using because it’s actually more expensive for some reason. There are plenty of those in hash tables: Things that get taught because they’re good in theory, but they’re bad in practice so nobody uses them.
Except somehow, on this one, the wires got crossed. Everyone uses the algorithm that’s unnecessarily slow and leads to more problems, and nobody is using the algorithm that’s faster while at the same time being more robust to problematic patterns. Knuth talked about Integer Modulo and about Fibonacci Hashing, and everybody should have taken away from that that they should use Fibonacci Hashing, but they didn’t and everybody uses integer modulo.
Before diving into this, let me just show you the results of a simple benchmark: Looking up items in a hash table:

In this benchmark I’m comparing various unordered_map implementations. I’m measuring their lookup speed when the key is just an integer. On the X-axis is the size of the container, the Y-axis is the time to find one item. To measure that, the benchmark is just spinning in a loop calling find() on this container, and at the end I divide the time that the loop took by the number of iterations in the loop. So on the left hand side, when the table is small enough to fit in cache, lookups are fast. On the right hand side the table is too big to fit in cache and lookups become much slower because we’re getting cache misses for most lookups.
But the main thing I want to draw attention to is the speed of ska::unordered_map, which uses Fibonacci hashing. Otherwise it’s a totally normal implementation of unordered_map: It’s just a vector of linked lists, with every element being stored in a separate heap allocation. On the left hand side, where the table fits in cache, ska::unordered_map can be more than twice as fast as the Dinkumware implementation of std::unordered_map, which is the next fastest implementation. (this is what you get when you use Visual Studio)
So if you use std::unordered_map and look things up in a loop, that loop could be twice as fast if the hash table used Fibonacci hashing instead of integer modulo.
How it works
So let me explain how Fibonacci Hashing works. It’s related to the golden ratio 


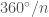

(The video is part two of a three-part series, part one is here)
I knew about that trick because it’s useful in procedural content generation: Any time that you want something to look randomly distributed, but you want to be sure that there are no clusters, you should at least try to see if you can use the golden ratio for that. (if that doesn’t work, Halton Sequences are also worth trying before you try random numbers) But somehow it had never occurred to me to use the same trick for hash tables.
So here’s the idea: Let’s say our hash table is 1024 slots large, and we want to map an arbitrarily large hash value into that range. The first thing we do is we map it using the above trick into the full 64 bit range of numbers. So we multiply the incoming hash value with 
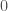

size_t fibonacci_hash_3_bits(size_t hash)
{
return (hash * 11400714819323198485llu) >> 61;
}
This will return the upper three bits after doing the multiplication with the magic constant. And we’re looking at just three bits because it’s easy to see how the golden ratio wraparound behaves when we just look at the top three bits. If we pass in some small numbers for the hash value, we get the following results from this:
fibonacci_hash_3_bits(0) == 0
fibonacci_hash_3_bits(1) == 4
fibonacci_hash_3_bits(2) == 1
fibonacci_hash_3_bits(3) == 6
fibonacci_hash_3_bits(4) == 3
fibonacci_hash_3_bits(5) == 0
fibonacci_hash_3_bits(6) == 5
fibonacci_hash_3_bits(7) == 2
fibonacci_hash_3_bits(8) == 7
fibonacci_hash_3_bits(9) == 4
fibonacci_hash_3_bits(10) == 1
fibonacci_hash_3_bits(11) == 6
fibonacci_hash_3_bits(12) == 3
fibonacci_hash_3_bits(13) == 0
fibonacci_hash_3_bits(14) == 5
fibonacci_hash_3_bits(15) == 2
fibonacci_hash_3_bits(16) == 7
This gives a pretty even distribution: The number 0 comes up three times, all other numbers come up twice. And every number is far removed from the previous and the next number. If we increase the input by one, the output jumps around quite a bit. So this is starting to look like a good hash function. And also a good way to map a number from a larger range into the range from 0 to 7.
In fact we already have the whole algorithm right here. All we have to do to get an arbitrary power of two range is to change the shift amount. So if my hash table is size 1024, then instead of just looking at the top 3 bits I want to look at the top 10 bits. So I shift by 54 instead of 61. Easy enough.
Now if you actually run a full hash function analysis on this, you find that it doesn’t make for a great hash function. It’s not terrible, but you will quickly find patterns. But if we make a hash table with a STL-style interface, we don’t control the hash function anyway. The hash function is being provided by the user. So we will just use Fibonacci hashing to map the result of the hash function into the range that we want.
The problems with integer modulo
So why is integer modulo bad anyways? Two reasons: 1. It’s slow. 2. It can be real stupid about patterns in the input data. So first of all how slow is integer modulo? If you’re just doing the straightforward implementation like this:
size_t hash_to_slot(size_t hash, size_t num_slots)
{
return hash % num_slots;
}
Then this is real slow. It takes roughly 9 nanoseconds on my machine. Which, if the hash table is in cache, is about five times longer than the rest of the lookup takes. If you get cache misses then those dominate, but it’s not good that this integer modulo is making our lookups several times slower when the table is in cache. Still the GCC, LLVM and boost implementations of unordered_map use this code to map the hash value to a slot in the table. And they are really slow because of this. The Dinkumware implementation is a little bit smarter: It takes advantage of the fact that when the table is sized to be a power of two, you can do an integer modulo by using a binary and:
size_t hash_to_slot(size_t hash, size_t num_slots_minus_one)
{
return hash & num_slots_minus_one;
}
Which takes roughly 0 nanoseconds on my machine. Since num_slots is a power of two, this just chops off all the upper bits and only keeps the lower bits. So in order to use this you have to be certain that all the important information is in the lower bits. Dinkumware ensures this by using a more complicated hash function than the other implementations use: For integers it uses a FNV1 hash. It’s much faster than a integer modulo, but it still makes your hash table twice as slow as it could be since FNV1 is expensive. And there is a bigger problem: If you provide your own hash function because you want to insert a custom type into the hash table, you have to know about this implementation detail.
We have been bitten by that implementation detail several times at work. For example we had a custom ID type that’s just a wrapper around a 64 bit integer which is composed from several sources of information. And it just so happens that that ID type has really important information in the upper bits. It took surprisingly long until someone noticed that we had a slow hash table in our codebase that could literally be made a hundred times faster just by changing the order of the bits in the hash function, because the integer modulo was chopping off the upper bits.
Other tables, like google::dense_hash_map also use a power of two hash size to get the fast integer modulo, but it doesn’t provide it’s own implementation of std::hash<int> (because it can’t) so you have to be real careful about your upper bits when using dense_hash_map.
Talking about google::dense_hash_map, integer modulo brings even more problems with it for open addressing tables it. Because if you store all your data in one array, patterns in the input data suddenly start to matter more. For example google::dense_hash_map gets really, really slow if you ever insert a lot of sequential numbers. Because all those sequential numbers get assigned slots right next to each other, and if you’re then trying to look up a key that’s not in the table, you have to probe through a lot of densely occupied slots before you find your first empty slot. You will never notice this if you only look up keys that are actually in the map, but unsuccessful lookups can be dozens of times slower than they should be.
Despite these flaws, all of the fastest hash table implementations use the “binary and” approach to assign a hash value to a slot. And then you usually try to compensate for the problems by using a more complicated hash function, like FNV1 in the Dinkumware implementation.
Why Fibonacci Hashing is the Solution
Fibonacci hashing solves both of these problems. 1. It’s really fast. It’s a integer multiplication followed by a shift. It takes roughly 1.5 nanoseconds on my machine, which is fast enough that it’s getting real hard to measure. 2. It mixes up input patterns. It’s like you’re getting a second hashing step for free after the first hash function finishes. If the first hash function is actually just the identity function (as it should be for integers) then this gives you at least a little bit of mixing that you wouldn’t otherwise get.
But really it’s better because it’s faster. When I worked on hash tables I was always frustrated by how much time we are spending on the simple problem of “map a large number to a small number.” It’s literally the slowest operation in the hash table. (outside of cache misses of course, but let’s pretend you’re doing several lookups in a row and the table is cached) And the only alternative was the “power of two binary and” version which discards bits from the hash function and can lead to all kinds of problems. So your options are either slow and safe, or fast and losing bits and getting potentially many hash collisions if you’re ever not careful. And everybody had this problem. I googled a lot for this problem thinking “surely somebody must have a good method for bringing a large number into a small range” but everybody was either doing slow or bad things. For example here is an approach (called “fastrange”) that almost re-invents Fibonacci hashing, but it exaggerates patterns where Fibonacci hashing breaks up patterns. It’s the same speed as Fibonacci hashing, but when I’ve tried to use it, it never worked for me because I would suddenly find patterns in my hash function that I wasn’t even aware of. (and with fastrange your subtle patterns suddenly get exaggerated to be huge problems) Despite its problems it is being used in Tensorflow, because everybody is desperate for a faster solution of this the problem of mapping a large number into a small range.
If Fibonacci Hashing is so great, why is nobody using it?
That’s a tricky question because there is so little information about Fibonacci hashing on the Internet, but I think it has to do with a historical misunderstanding. In The Art of Computer Programming, Knuth introduces three hash functions to use for hash tables:
- Integer Modulo
- Fibonacci Hashing
- Something related to CRC hashes
The inclusion of the integer modulo in this list is a bit weird from today’s perspective because it’s not much of a hash function. It just maps from a larger range into a smaller range, and doesn’t otherwise do anything. Fibonacci hashing is actually a hash function, not the greatest hash function, but it’s a good introduction. And the third one is too complicated for me to understand. It’s something about coming up with good coefficients for a CRC hash that has certain properties about avoiding collisions in hash tables. Probably very clever, but somebody else has to figure that one out.
So what’s happening here is that Knuth uses the term “hash function” differently than we use it today. Today the steps in a hash table are something like this:
- Hash the key
- Map the hash value to a slot
- Compare the item in the slot
- If it’s not the right item, repeat step 3 with a different item until the right one is found or some end condition is met
We use the term “hash function” to refer to step 1. But Knuth uses the term “hash function” to refer to something that does both step 1 and step 2. So when he refers to a hash function, he means something that both hashes the incoming key, and assigns it to a slot in the table. So if the table is only 1024 items large, the hash function can only return a value from 0 to 1023. This explains why “integer modulo” is a hash function for Knuth: It doesn’t do anything in step 1, but it does work well for step 2. So if those two steps were just one step, then integer modulo does a good job at that one step since it does a good job at our step 2. But when we take it apart like that, we’ll see that Fibonacci Hashing is an improvement compared to integer modulo in both steps. And since we’re only using it for step 2, it allows us to use a faster implementation for step 1 because the hash function gets some help from the additional mixing that Fibonacci hashing does.
But this difference in terms, where Knuth uses “hash function” to mean something different than “hash function” means for std::unordered_map, explains to me why nobody is using Fibonacci hashing. When judged as a “hash function” in today’s terms, it’s not that great.
After I found that Fibonacci hashing is not mentioned anywhere, I did more googling and was more successful searching for “multiplicative hashing.” Fibonacci hashing is just a simple multiplicative hash with a well-chosen magic number. But the language that I found describing multiplicative hashing explains why nobody is using this. For example Wikipedia has this to say about multiplicative hashing:
Multiplicative hashing is a simple type of hash function often used by teachers introducing students to hash tables. Multiplicative hash functions are simple and fast, but have higher collision rates in hash tables than more sophisticated hash functions.
So just from that, I certainly don’t feel encouraged to check out what this “multiplicative hashing” is. Or to get a feeling for how teachers introduce this, here is MIT instructor Erik Demaine (who’s videos I very much recommend) introducing hash functions, and he says this:
I’m going to give you three hash functions. Two of which are, let’s say common practice, and the third of which is actually theoretically good. So the first two are not good theoretically, you can prove that they’re bad, but at least they give you some flavor.
Then he talks about integer modulo, multiplicative hashing, and a combination of the two. He doesn’t mention the Fibonacci hashing version of multiplicative hashing, and the introduction probably wouldn’t inspire people to go seek out more information it.
So I think people just learn that multiplicative hashing is not a good hash function, and they never learn that multiplicative hashing is a great way to map large values into a small range.
Of course it could also be that I missed some unknown big downside to Fibonacci hashing and that there is a real good reason why nobody is using this, but I didn’t find anything like that. But it could be that I didn’t find anything bad about Fibonacci hashing simply because it’s hard to find anything at all about Fibonacci hashing, so let’s do our own analysis:
Analyzing Fibonacci Hashing
So I have to confess that I don’t know much about analyzing hash functions. It seems like the best test is to see how close a hash function gets to the strict avalanche criterion which “is satisfied if, whenever a single input bit is changed, each of the output bits changes with a 50% probability.”
To measure that I wrote a small program that takes a hash 
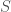


I then run that same test every time after I doubled a hash table, because with different size hash tables there are more bits in the output: If the hash table only has four slots, there are only two bits in the output. If the hash table has 1024 slots, there are ten bits in the output. Finally I color code the result and plot the whole thing as a picture that looks like this:

Let me explain this picture. Each row of pixels represents one of the 64 bits of the input hash. The bottom-most row is the first bit, the topmost row is the 64th bit. Each column represents one bit in the output. The first two columns are the output bits for a table of size 4, the next three columns are the output bits for a table of size 8 etc. until the last 23 bits are for a table of size eight million. The color coding means this:
- A black pixel indicates that when the input pixel for that row changes, the output pixel for that column has a 50% chance of changing. (this is ideal)
- A blue pixel means that when the input pixel changes, the ouput pixel has a 100% chance of changing.
- A red pixel means that when the input pixel changes, the output pixel has a 0% chance of changing.
For a really good hash function the entire picture would be black. So Fibonacci hashing is not a really good hash function.
The worst pattern we can see is at the top of the picture: The last bit of the input hash (the top row in the picture) can always only affect the last bit of the output slot in the table. (the last column of each section) So if the table has 1024 slots, the last bit of the input hash can only determine the bit in the output slot for the number 512. It will never change any other bit in the output. Lower bits in the input can affect more bits in the output, so there is more mixing going on for those.
Is it bad that the last bit in the input can only affect one bit in the output? It would be bad if we used this as a hash function, but it’s not necessarily bad if we just use this to map from a large range into a small range. Since each row has at least one blue or black pixel in it, we can be certain that we don’t lose information, since every bit from the input will be used. What would be bad for mapping from a large range into a small range is if we had a row or a column that has only red pixels in it.
Let’s also look at what this would look like for integer modulo, starting with integer modulo using prime numbers:

This one has more randomness at the top, but a clearer pattern at the bottom. All that red means that the first few bits in the input hash can only determine the first few bits in the output hash. Which makes sense for integer modulo. A small number modulo a large number will never result in a large number, so a change to a small number can never affect the later bits.
This picture is still “good” for mapping from a large range into a small range because we have that diagonal line of bright blue pixels in each block. To show a bad function, here is integer modulo with a power of two size:

This one is obviously bad: The upper bits of the hash value have completely red rows, because they will simply get chopped off. Only the lower bits of the input have any effect, and they can only affect their own bits in the output. This picture right here shows why using a power of two size requires that you are careful with your choice of hash function for the hash table: If those red rows represent important bits, you will simply lose them.
Finally let’s also look at the “fastrange” algorithm that I briefly mentioned above. For power of two sizes it looks really bad, so let me show you what it looks like for prime sizes:

What we see here is that fastrange throws away the lower bits of the input range. It only uses the upper bits. I had used it before and I had noticed that a change in the lower bits doesn’t seem to make much of a difference, but I had never realized that it just completely throws the lower bits away. This picture totally explains why I had so many problems with fastrange. Fastrange is a bad function to map from a large range into a small range because it’s throwing away the lower bits.
Going back to Fibonacci hashing, there is actually one simple change you can make to improve the bad pattern for the top bits: Shift the top bits down and xor them once. So the code changes to this:
size_t index_for_hash(size_t hash)
{
hash ^= hash >> shift_amount;
return (11400714819323198485llu * hash) >> shift_amount;
}
It’s almost looking more like a proper hash function, isn’t it? This makes the function two cycles slower, but it gives us the following picture:

This looks a bit nicer, with the problematic pattern at the top gone. (and we’re seeing more black pixels now which is the ideal for a hash function) I’m not using this though because we don’t really need a good hash function, we need a good function to map from a large range into a small range. And this is on the critical path for the hash table, before we can even do the first comparison. Any cycle added here makes the whole line in the graph above move up.
So I keep on saying that we need a good function to map from a large range into a small range, but I haven’t defined what “good” means there. I don’t know of a proper test like the avalanche analysis for hash functions, but my first attempt at a definition for “good” would be that every value in the smaller range is equally likely to occur. That test is very easy to fulfill though: all of the methods (including fastrange) fulfill that criteria. So how about we pick a sequence of values in the input range and check if every value in the output is equally likely. I had given the examples for numbers 0 to 16 above. We could also do multiples of 8 or all powers of two or all prime numbers or the Fibonacci numbers. Or let’s just try as many sequences as possible until we figure out the behavior of the function.
Looking at the above list we see that there might be a problematic pattern with multiples of 4: fibonacci_hash_3_bits(4) returned 3, for fibonacci_hash_3_bits(8) returned 7, fibonacci_hash_3_bits(12) returned 3 again and fibonacci_hash_3_bits(16) returned 7 again. Let’s see how this develops if we print the first sixteen multiples of four:
Here are the results:
0 -> 0
4 -> 3
8 -> 7
12 -> 3
16 -> 7
20 -> 2
24 -> 6
28 -> 2
32 -> 6
36 -> 1
40 -> 5
44 -> 1
48 -> 5
52 -> 1
56 -> 4
60 -> 0
64 -> 4
Doesn’t look too bad actually: Every number shows up twice, except the number 1 shows up three times. What about multiples of eight?
0 -> 0
8 -> 7
16 -> 7
24 -> 6
32 -> 6
40 -> 5
48 -> 5
56 -> 4
64 -> 4
72 -> 3
80 -> 3
88 -> 3
96 -> 2
104 -> 2
112 -> 1
120 -> 1
128 -> 0
Once again doesn’t look too bad, but we are definitely getting more repeated numbers. So how about multiples of sixteen?
0 -> 0
16 -> 7
32 -> 6
48 -> 5
64 -> 4
80 -> 3
96 -> 2
112 -> 1
128 -> 0
144 -> 7
160 -> 7
176 -> 6
192 -> 5
208 -> 4
224 -> 3
240 -> 2
256 -> 1
This looks a bit better again, and if we were to look at multiples of 32 it would look better still. The reason why the number 8 was starting to look problematic was not because it’s a power of two. It was starting to look problematic because it is a Fibonacci number. If we look at later Fibonacci numbers, we see more problematic patterns. For example here are multiples of 34:
0 -> 0
34 -> 0
68 -> 0
102 -> 0
136 -> 0
170 -> 0
204 -> 0
238 -> 0
272 -> 0
306 -> 0
340 -> 1
374 -> 1
408 -> 1
442 -> 1
476 -> 1
510 -> 1
544 -> 1
That’s looking bad. And later Fibonacci numbers will only look worse. But then again how often are you going to insert multiples of 34 into a hash table? In fact if you had to pick a group of numbers that’s going to give you problems, the Fibonacci numbers are not the worst choice because they don’t come up that often naturally. As a reminder, here are the first couple Fibonacci numbers: 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584… The first couple numbers don’t give us bad patterns in the output, but anything bigger than 13 does. And most of those are pretty harmless: I can’t think of any case that would give out multiples of those numbers. 144 bothers me a little bit because it’s a multiple of 8 and you might have a struct of that size, but even then your pointers will just be eight byte aligned, so you’d have to get unlucky for all your pointers to be multiples of 144.
But really what you do here is that you identify the bad pattern and you tell your users “if you ever hit this bad pattern, provide a custom hash function to the hash table that fixes it.” I mean people are happy to use integer modulo with powers of two, and for that it’s ridiculously easy to find bad patterns: Normal pointers are a bad pattern for that. Since it’s harder to come up with use cases that spit out lots of multiples of Fibonacci numbers, I’m fine with having “multiples of Fibonacci numbers” as bad patterns.
So why are Fibonacci numbers a bad pattern for Fibonacci hashing anyways? It’s not obvious if we just have the magic number multiplication and the bit shift. First of all we have to remember that the magic constant came from dividing by the golden ratio: 

I’m leaving out the shift at the end because that part doesn’t matter for figuring out why Fibonacci numbers are giving us problems. In the example of stepping around a circle (from the Vi Hart video above) the equation would look like this:

This would give us an angle from 0 to 360. These functions are obviously similar. We just replaced 

Where 
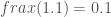


What we see here is that if we divide a Fibonacci number by the golden ratio, we just get the previous Fibonacci number. There is no fractional part so we always end up with 0. So even if we multiply the full range of
Except that when we talk about badness, we also have to consider the size of the hash table. It’s really easy to find bad patterns when the table only has eight slots. If the table is bigger and has, say 64 slots, suddenly multiples of 34 don’t look as bad:
0 -> 0
34 -> 0
68 -> 1
102 -> 2
136 -> 3
170 -> 4
204 -> 5
238 -> 5
272 -> 6
306 -> 7
340 -> 8
374 -> 9
408 -> 10
442 -> 10
476 -> 11
510 -> 12
544 -> 13
And if the table has 1024 slots we get all the multiples nicely spread out:
0 -> 0
34 -> 13
68 -> 26
102 -> 40
136 -> 53
170 -> 67
204 -> 80
238 -> 94
272 -> 107
306 -> 121
340 -> 134
374 -> 148
408 -> 161
442 -> 175
476 -> 188
510 -> 202
544 -> 215
At size 1024 even the multiples of 144 don’t look scary any more because they’re starting to be spread out now:
0 -> 0
144 -> 1020
288 -> 1017
432 -> 1014
576 -> 1011
720 -> 1008
864 -> 1004
1008 -> 1001
1152 -> 998
So the bad pattern of multiples of Fibonacci numbers goes away with bigger hash tables. Because Fibonacci hashing spreads out the numbers, and the bigger the table is, the better it gets at that. This doesn’t help you if your hash table is small, or if you need to insert multiples of a larger Fibonacci number, but it does give me confidence that this “bad pattern” is something we can live with.
So I am OK with living with the bad pattern of Fibonacci hashing. It’s less bad than making the hash table a power of two size. It can be slightly more bad than using prime number sizes, as long as your prime numbers are well chosen. But I still think that on average Fibonacci hashing is better than prime number sized integer modulo, because Fibonacci hashing mixes up sequential numbers. So it fixes a real problem I have run into in the past while introducing a theoretical problem that I am struggling to find real examples for. I think that’s a good trade.
Also prime number integer modulo can have problems if you choose bad prime numbers. For example boost::unordered_map can choose size 196613, which is 0b110000000000000101 in binary, which is a pretty round number in the same way that 15000005 is a pretty round number in decimal. Since this prime number is “too round of a number” this causes lots of hash collisions in one of my benchmarks, and I didn’t set that benchmark up to find bad cases like this. It was totally accidental and took lots of debugging to figure out why boost::unordered_map does so badly in that benchmark. (the benchmark in question was set up to find problems with sequential numbers) But I won’t go into that and will just say that while prime numbers give fewer problematic patterns than Fibonacci hashing, you still have to choose them well to avoid introducing hash collisions.
Conclusion
Fibonacci hashing may not be the best hash function, but I think it’s the best way to map from a large range of numbers into a small range of numbers. And we are only using it for that. When used only for that part of the hash table, we have to compare it against two existing approaches: Integer modulo with prime numbers and Integer modulo with power of two sizes. It’s almost as fast as the power of two size, but it introduces far fewer problems because it doesn’t discard any bits. It’s much faster than the prime number size, and it also gives us the bonus of breaking up sequential numbers, which can be a big benefit for open addressing hash tables. It does introduce a new problem of having problems with multiples of large Fibonacci numbers in small hash tables, but I think those problems can be solved by using a custom hash function when you encounter them. Experience will tell how often we will have to use this.
All of my hash tables now use Fibonacci hashing by default. For my flat_hash_map the property of breaking up sequential numbers is particularly important because I have had real problems caused by sequential numbers. For the others it’s just a faster default. It might almost make the option to use the power of two integer modulo unnecessary.
It’s surprising that the world forgot about this optimization and that we’re all using primer number sized hash tables instead. (or use Dinkumware’s solution which uses a power of two integer modulo, but spends more time on the hash function to make up for the problems of the power of two integer modulo) Thanks to Rich Geldreich for writing a hash table that uses this optimization and for mentioning it in my comments. But this is an interesting example because academia had a solution to a real problem in existing hash tables, but professors didn’t realize that they did. The most likely reason for that is that it’s not well known how big the problem of “mapping a large number into a small range” is and how much time it takes to do an integer modulo.
For future work it might be worth looking into Knuth’s third hash function: The one that’s related to CRC hashes. It seems to be a way to construct a good CRC hash function if you need a n-bit output for a hash table. But it was too complicated for me to look into, so I’ll leave that as an exercise to the reader to find out if that one is worth using.
Finally here is the link to my implementation of unordered_map. My other two hash tables are also there: flat_hash_map has very fast lookups and bytell_hash_map is also very fast but was designed more to save memory compared to flat_hash_map.

You can also use fast range reduction: https://lemire.me/blog/2016/06/27/a-fast-alternative-to-the-modulo-reduction/
It’s also super fast (a multiply and a shift), but the nice part about it is that you can map it to any sized range, not just powers of two (so e.g. you can grow your hash table by 1.5x each time, instead of 2.. or use prime number sizes, or whatever you want).
Oh just realized you briefly mentioned it. IMO you’re not giving it enough credit.. neither fibonacci or fastrange will work as a hash function alone, you need a decent hash function to start with, and the benefits of fastrange is that it allows you to use non-pow-of-2 sizes (if you do use power of two sizes it’s true that it’s exactly equivalent to just throwing away the lower bits). You could do the trick you do above of xor-ing in the low bits into the high bits before mapping to precondition it a bit and ensure you don’t throw a way the low bits completely (but the original hash function should already have done plenty such mixing).
Why does Fibonacci hashing not work as a hash function alone? It should, unless you have a use case that results in lots of Fibonacci numbers being inserted. You can use the identity function as the hash when you use Fibonacci hashing to assign a hash to an index. In fact you can also use the identity function when using prime number sizes. Only for power of two sizes and for fastrange do you need a separate hash function. Or when your type is bigger than 64 bits obviously.
Since both the hash function, and the function that you use to map from the hash value to a slot are on the critical path of the hash table, you want to be very careful what you do in there. If the hash function can be identity, it should be identity. And the cases where it can’t be identity are pretty rare. (except of course when using power of two sizes or when using fastrange, then those cases are common)
I think it is possible to improve fastrange so that it also uses the low bits, but why not just use Fibonacci hashing? To improve fastrange you would have to slow it down. Fibonacci hashing is already the same speed and gives better results.
Can’t reply to Malte (no reply button), so I’ll reply here. The reason you need another hash function is that you can be hashing arbitrary length things like strings, and you haven’t supplied an iterative version of the Fibonacci hash.
A few thoughts: You literally say “Fibonacci hashing is not a really good hash function.” in the article. Then you proceed to add a really ghetto hashing algorithm preprocessing step to improve it somewhat. Having a real hash function like xxHash (or for integer->integer, the permutation step from PCG, perhaps) should be much better. As far as I can tell your argument here basically boils down to “sometimes a bad hash function is okay, if we do some post processing on it”, which is true, but there are many ways of doing such post processing, and in fact hashing functions do just this to get their final output.
Second, fast range preserves the order of elements regardless of table size. So when resizing you can do a linear scan to move elements into the new table. This is faster.
Third, it allows arbitrary sizes. I don’t understand your comment that Fibonacci works with prime sizes. Maybe I missed something, but you don’t seem to show that you can use Fibonacci hashing with arbitrary sizes (do you mean by adding an integer modulo at the end? That’s the whole thing we’re trying to avoid.. fast range doesn’t need modulo).
I don’t think you need to improve fast range, I think it works just fine with a decent hash function, which I think is fair to assume for someone using a hash table (xxHash does 10+GB/s, there’s no real excuse to not use a decent hash function).
Finally, as Grant Husbands points out – I’d wager most uses of a hash table isn’t with an integer key – you need a hash function anyway.
Alright sorry, this needs a lot more clarification. So first of all the “prime number sizes” was referring to prime number integer modulo.
Then we have two cases:
1. The type is smaller than 64 bits. This includes ints, floats, small custom structs or small std::pairs.
2. The type is variable size or larger than 64 bits. This includes std::string and other sequences.
Now we can break down point 1 more:
1.1 You are not inserting lots of multiples of Fibonacci numbers into your table. This is the usual case. In this case just use Fibonacci hashing. And use the identity function for the hash function. Adding a custom hashing function on top would just slow you down unnecessarily.
1.2 You have a pattern that has problems with Fibonacci hashing. In this case use prime number integer modulo. I didn’t mention this in the blog post, but it can actually also be made faster. If you look at flat_hash_map.hpp in my repository you will see a huge code block dedicated to making prime number integer modulo faster. And with a compile time switch you can use this behavior. (define the hash_policy typedef in your hash type. See the power_of_two_std_hash struct as an example that just uses std::hash but uses the power of two integer modulo policy) But once again even with a prime number integer modulo, you want to use the identity function as your hash function, because there is no reason to use anything more complicated.
There are very, very few other cases. The only other case I would maybe consider is if you’re super confident that all the information is in the lower bits. Then you can use power of two sized integer modulo and get a tiny speed up over Fibonacci hashing. But now you’re playing with fire, because if your inputs ever change you’ll get hash collisions. Fibonacci hashing is the safer choice and it’s not much slower.
When would you use fastrange? Never. If you know the information is in the upper bits, you could use fastrange. But then you could also use Fibonacci hashing because it’s the same speed but it uses all the bits.
Let’s break down point 2, too:
2.1. The type already has a good hash function. For example std::string. In this case you want to use power of two sized integer modulo. I have been thinking of doing that by default for strings. If there is already a good hash function, there is no reason to use anything more complicated. You’d just be adding cost on top of the hash function.
2.2. You have to write a hash function for the type. In that case use an existing hash function. If you use a good one, just use power of two sized integer modulo, if you use a bad one (maybe because it’s faster) use Fibonacci hashing.
So what we have here is that in the most common cases you want to use Fibonacci hashing, or if you already have a good hash function, you want to use power of two sized integer modulo because that is simply the fastest thing, and you don’t need anything more fancy if you have a good hash function. There are no cases where you want to use fastrange.
So what about the benefits of “preserving order independent of size” or “it allows arbitrary sizes”? I don’t know, man. Why are those big benefits? It’s fairly standard to just double the size of the table on resize. I even do that for my prime number size table, where I could grow in smaller steps. And I doubt I can take advantage of the items being in a certain order. Once you get a few hash collision you have to resolve those and shuffle items around. And that will play out different depending on the size. (when you double the size you get fewer collisions and thus a different order of your elements) So you can’t rely on things being in a certain order, so I really don’t know what benefit you get from the results of the hash function being in the same order. Also even if they were in the same order, they won’t be in the same position. So you can’t just memcpy. And otherwise the loop that you do when resizing is already really simple, so I struggle to come up with a way to simplify it more, even if you could know that items were in the same order. Plus, how often do you resize your hash table? If you use fastrange you’re inviting a lot of problems and thus a lot of complexity. Maybe you now have to use a slower hash function (like xxHash instead of the identity function) because fastrange otherwise gives you problems. How many of those slowdowns and problems are you willing to add just to make table resizing faster? It’s just putting the priorities in the wrong place. You should make sure that your lookups are fast, not your table resizing.
I think there is a common misunderstanding where people are really, really scared of bad inputs and are thus saying that “you always have to run a proper hash function on the input.” That is simply wrong. If you use prime number integer modulo you are fine. If you use Fibonacci hashing, you are fine. You don’t need a perfect distribution. So just use the identity function when you can, and only use a more expensive hash function when you have to. (when the type is bigger or variable size) Yes, there are certain patterns that can hurt you, but those are very, very rare. When picking these defaults you have to consider that everyone is going to use them. You don’t want to slow down the common case in order to make the very, very rare case faster. I admit that this is a trade-off. For example I do slow down the common case by not using power of two sized integer modulo. If I did that, the common case would be even faster. But there are too many inputs that break for power of two sized integer modulo, so I’m not happy to use that as the default. Where for Fibonacci hashing, bad inputs are “very, very rare” for power of two sized integer modulo bad inputs are common. But part of the reason why Fibonacci hashing is so brilliant is that it’s a great trade-off here. It’s really fast while also being really good at reducing the range. So use that and use the identity hasher by default.
Re: 1.1, I feel like your argument can be restated as “sometimes multiplicative hashing works okay, even though it’s a terrible hash function”. And yes that’s true, but this is an argument for weak hashing being practical in some cases, but obviously this isn’t true in all cases and you seem weirdly excited about this particular version as if it’s not just another weak hash function. IMO there are much better behaved ways of turning an int into a reasonably uniform int (see the permutation step of PCG, for example) that are still cheap but behave much better than multiplicative hashing.
Re: 1.2 As I’m sure you’re aware, fibonacci numbers come up *all the time* naturally. Seems kind of like a double standard to make the assumption that the input is not going to play badly with your particularly chosen weak hash function, while in the other hand complain that fast range behave poorly on (very) weak hash functions.
You sort of just side step the fact that fast range doesn’t need any clever tricks to avoid integer modulo. It “just works”. The reason you don’t want power of two table sizes is two-fold: 1) It wastes memory. 2) It plays poorly with the allocator. To elaborate on that last point, if you use a growth factor of 1.5x, it’s more likely that you can reuse previously used memory blocks which is more efficient (so e.g. 4, then 6, then 9 – when allocating the array for 9 elemens, the previous two can be merged and reused because 4+6>9).
The reason preserving order is good is because it speeds up re-insertion. It becomes a linear scan over the new and old arrays rather than having to jump around all over the new one because the order changed. For small hash tables in particular, the cost of growth can be very signficant average overhead, and for large table it can be extremely bad for predictability. You have to make sure when you move an element to the new table that it’s at “at least” its “target slot” (because the new table is bigger, you’ll want to insert some “holes” occasionally) but memory access is much better.
BTW, re: the allocator-aware growth thing: you do have to make sure you use “realloc” for that to work, *and* that your allocator tries to merge blocks like that, but it’s fairly standard to use 1.5.x instead of 2x for this reason. Unfortunately with C++ not all types can be realloc’d.
I also just realized that the allocation block sizes for the aforementioned allocator-aware growth strategy is a Fibonacci sequence. That’s just ironic and drives home the point that the Fibonacci sequence is literally famous for showing up all over in unexpected places.
I think my broader point is: The user can already customize the hash function. If they have well behaved data and want to use a weak hash (like Fibonacci, or any other) then they already can. This shouldn’t be something the table does on top of what the user’s hash function returns.
If you made the growth factor customizible too, you could special case it for growth=2 and do just plain shifting in that case (but tbh I wouldn’t be surprised if you found that fast range performed the same in practice.. theoretically a simple shift may be simpler than a multiply (esp. for 32 bit hashes), but in practice, does it make a difference in a superscalar CPU? Maybe, maybe not)
For the realloc strategy: It’s a clever trick, but I can’t use it because I am using std::allocator. Yes, nobody likes std::allocator, but if you want to be interface-compatible with std::unordered_map, you have to use it. And I think it is very important to be interface-compatible with std::unordered_map. Also, as you observed yourself, in a generic hash table you can’t use the trick anyway because you need to keep the old block around because you need to move-construct from the old block into the new one. So there is no time where the allocator could merge the old blocks because the hash table is still holding on to it, and it will only be freed once the data has been transfered to the larger block.
For the “sometimes multiplicative hashing works okay, even though it’s a terrible hash function” thing: I think “terrible” is too strong of a word, but that’s besides the point because my argument is actually even stronger: It literally doesn’t matter how good of a hash function it is. I think part of the problem is that I couldn’t come up with a good measure for what makes a function be a good mapping function from a large range into a small range. If a function is a good hash function, then it will also be a good function to map from a large range into a small range, (just chop off the top bits after hashing) but it can also be a good function for that purpose even if it’s a bad hash function. To illustrate that, lets consider the case of prime number integer modulo, which I think everyone would agree is a really terrible hash function.
As I mentioned in the blog post, most unordered_map implementations use a prime number sized integer modulo, and then just use the identity function as the hash function for integer types. Why do they do that? These hash tables were written by really smart people. Why would smart people decide to use no hash function at all and to only rely on the mapping function of the prime number integer modulo? Because it’s a really good trade-off when you look at all the different considerations of a hash table. I actually think it’s a better decision than what Dinkumware did where they went with a power of two size and a more complex hash function. The other unordered_map implementations should just use a faster integer modulo like I do in my prime_number_hash_policy, then they would beat Dinkumware both in performance, and they would have fewer problems than Dinkumware.
Now it may sound like heresy to say that you’d get fewer problems with the identity hash function, but it really is true. Because all you need is that every slot in the table is equally likely to be used. Prime number integer modulo gives you that. You can check this with all kinds of patterns, and you will always find that every slot is equally likely to be used. Of course you can always construct patterns that intentionally break the hash table, but that is always the case, even if you use a really complicated hash function. But if you can show me a real pattern that comes up in real code that breaks prime number integer modulo, then I will consider using a more complicated hash function. If you can’t, then it is a good solution. If you have to artificially construct inputs to find a weakness, then it is a good solution.
The other thing to consider is that hash tables have the customization point of providing your own hash function. And lots of people use that customization point because lots of people want to store their own types in hash tables. So now the hash table has to decide on some method of turning the result from the user provided hash function into a slot in the table. If you use power of two sized integer modulo, there are lots of traps to fall into for your users, but prime number integer modulo stays robust. I think this is also very important, and this is why I think Dinkumware made the wrong choice by just chopping off the upper bits. Your users won’t necessarily know how to write a good hash function, and the table has to be somewhat robust against that. Fastrange is really not robust against bad hash functions. It has all the same problems of power of two sized integer modulo, because it just chops off the bottom bits. (I actually think it has more problems because the bottom bits more often have information in it) Fibonacci hashing is robust in the same way that prime number integer modulo is robust: I don’t know of a real pattern that comes up in real code that would break it. I know how to break it if I want to, but I can’t come up with any situation where I would break it in real code. I will say that I wouldn’t at all be surprised if I will soon come across such a use case, but I haven’t yet, and it doesn’t make sense to be scared to use something because maybe someday I will potentially run into a problem with it, even though right now it looks like I never will. If you think like that, you shouldn’t use hash tables at all.
So that brings me to this part of your comment:
“The user can already customize the hash function. If they have well behaved data and want to use a weak hash (like Fibonacci, or any other) then they already can. This shouldn’t be something the table does on top of what the user’s hash function returns.”
The beauty of Fibonacci hashing is that it does two jobs in one: 1. It maps the number from a large range into a small range (which the hash table definitely has to do) and 2. It does some additional mixing of the inputs. So yes, the table doesn’t have to do any hashing on top of what the user does, but it does have to map the number that the user provides into a small range. If we can get some additional hashing at the same time for free, that’s great.
There is also one meta-problem with this discussion, which is that when talking about hash tables, you can always come up with situations where one table is faster than another. Give me your fastest hash table, and I will come up with a situation where std::unordered_map is faster. So the discussion can’t be about “I found a case where your table is slower than another” but it has to be about weighing different trade-offs and about deciding what’s important to be fast.
For me, when considering various trade-offs, it’s always important for lookups to be as fast as possible. So when we talk about how much better the behavior would be when using a more complicated hash function, you really have to think about how much slower or faster your average lookup will be. Let’s say you use a more complicated hash function like xxHash. If you insert random numbers, you immediately find that your lookups are now more than twice as slow as Fibonacci hashing when the table is cached. Bummer. So now instead of random numbers we throw a bunch of different use cases at the hash tables. Because xxHash will give us fewer hash collisions when we insert non-random numbers. How much do you think hash collisions will go down? 1 percent? 5 percent? Enough to make up for a factor two difference in speed? Because if you can’t drastically reduce hash collisions, your table won’t be any faster and you are only losing by using a more complicated hash function. And you can’t reduce hash collisions much compared to Fibonacci hashing, because there are already very few hash collisions with Fibonacci hashing.
And even if you find a use case where Fibonacci hashing does badly and you want to use a more complicated hash function like xxHash, you should try using prime number integer modulo first. It’s very easy to change that in my hash tables, just use the prime_number_hash_policy. That is still twice as fast as using xxHash, and it will definitely handle your pattern. If it doesn’t, then I would actually be really interested in that. I have a collection of bad cases that break hash tables, and I am always looking for more of those. They have to be real cases though, not artificial constructs. Because when it comes to hash tables you can always come up with edge cases where a hash table does really badly.
Coming back to this conversation months later: I actually had a use case where I needed to save as much space as possible, so I wanted to pack the hash table as tight as possible. Which, as you pointed out, fibonacci hashing doesn’t support because the table has to be sized to be a power of two. But fastrange also didn’t work because I got too many hash collisions with that. Integer modulo with constants would have worked and was fairly fast, (faster than trying to fix the hash collisions in fastrange) but it was then that I realized that a combination of fibonacci hashing and fastrange actually makes a lot of sense: Fibonacci hashing gives you a good mixing of the upper bits, and fastrange only looks at the upper bits. So I ended up using fibonacci hashing followed by fastrange to make it possible to give the container an arbitrary size. It was still faster than any alternative and saved me a lot of disk space and memory.
Didn’t finish reading yet, just a correction: I think you got Rich Geldreich’s name wrong in the third paragraph. Please feel free to delete this comment later.
Thanks! Fixed.
The graph is too small, the legend is unreadable.
Thanks for pointing it out. I made the font larger.
In the graphs of the odds of a bit changing, blue and black are a little hard to tell apart, but you probably already know that.
For a production example, Snappy uses multiplicative hashing:
https://github.com/google/snappy/blob/master/snappy.cc#L65
Originally (before the open-source release), it used a different constant that was much closer to the golden ratio, which also worked well. I remember at some point just brute-forcing all 2^32 constants to see if any did markedly better on the test set, but it really doesn’t matter all that much.
Thanks! Do you know why that constant was chosen? I also looked into a lot of different constants as alternatives to the golden ratio, but every time that I tried a new number I discovered a new way that multiplicative hashing can break. In the end I had to conclude that the golden ratio really is a very good choice. I am certain that there are other good choices out there, and I wouldn’t be surprised if there were better choices than the golden ratio, I just don’t know how to go looking for them.
Oh and the ways in which it can break can be subtle. Like for a certain constant I might find “if the hash table is either size 32768 or size 65536 then you get more collisions, in all other cases it’s better than the golden ratio.” Or I would find it being better in the general case but being worse in specific tests where I insert numbers with specific patterns. It was really hard to predict which number would do well, but somehow the golden ratio always did well.
The brotli code actually has some of the properties they were looking for when searching out this number as well as referencing some heuristic of which they ran tests in order to optimize this for. Interesting you can see this number popping up in a number of open sourced google tools that need extremely fast hashing (snappy, brotli, webp).
https://github.com/google/brotli/blob/master/c/enc/hash.h#L79
The choice of constant was in a sense a bit political (I never really agreed with it). IIRC it was based on good distribution of some common English byte sequences (e.g. ” the” and similar) in Brotli, and someone(TM) wanted Snappy and Brotli to use the same hash constant. It didn’t really matter much for any of the tests we had at the time, so it went through.
The previous one was a) close to the golden ratio, b) prime, and c) had each sub-byte within some special set of ranges as described by Knuth. IIRC all of these actually helped a tiny bit on the benchmarks when we changed the hash (it was originally something that was home-grown and both quite bad and slow), but the latter was so microscopic that it could just have been luck.
Just a crazy out of the blue idea here.
Next to the gold, there are other “metalic” ratios. If cheap enough to do, why not pick two of the available, execute them in parallel (well the CPU will do that for you) and mix the result?
My guesstimate is that it will no longer match natural occurring patters, while still showing some sort of unique spread. That or the emergence of a disastrous interfering pattern, but I think that is a bit less likely with there kind of ratios.
Now onto a totally different line of thought. Are multipliers not known for cooking your CPU, like in consuming lots of power? That should have an effect on clock-speed in stressing scenarios. There must be something to say for choosing an energy efficient method in today’s auto tuning CPUs with many cores on the same chip.
Granted a measured 2x speedup for common cases is likely worth it, but in less extreme situations, higher overall clocks is a safer bet I think. But man, will this be hard to benchmark objectively.
Nice article. Your hash function seems to be an instance of a near-universal family called binary multiplicative hashing.
If you mainly care about speed, you should use xor + bit mask instead of a multiplicative hash:
Android (C++): https://android.googlesource.com/platform/system/core/+/master/libcutils/hashmap.cpp#83
Java SDK: http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/classes/java/util/HashMap.java#l320
By the way, I found this post from Hacker News: https://news.ycombinator.com/item?id=17328756
I think if you go down the path of xor+shift, and you try to make it good, you will get Knuth’s third hash function, which I briefly mentioned in the blog post. And I think it’s worth investigating, I just don’t have the time to do it. My prediction is that it may be faster for 32 bit hashes but it will be slower for 64 bit hashes because you have to do more operations to mix in all the bits.
The C++ code you linked to is already slower than Fibonacci hashing. It does two additions, two xors, one bit negation, four shifts and one binary and. The single multiplication followed by a single shift of Fibonacci hashing is going to be faster than that. Just to be sure I actually measured it, and it just comes out slower. Which isn’t surprising because there is no reason why it should be faster.
The other thing to consider with that C++ code is that it is written for a 32 bit hashtable. If you’re on a 64 bit platform you have to mix in more bits, so you probably have to do even more operations and it would be even slower. Or you just continue to use 32 bit hashes even on 64 bit platforms, but now you’re not compatible with the interface of std::unordered_map. And you can’t just chop off the top 32 bits because the whole point of this was to use all the bits.
The Java code may be fast since it just does a shift, xor and a binary and. But I don’t think it’ll be good. For example I think the very common pattern of inserting pointers will still give you lots of hash collisions with this. If your pointers are eight bytes aligned, you are losing three bits at the bottom. The code is hoping that by shifting exactly 16 bits over you are getting three more helpful bits mixed in. And maybe that’s the case in Java, because maybe they wrote their allocator to work like that, but I wouldn’t rely on that in general. If you’ve looked at a lot of pointers, you see that they have very clear patterns, and so it wouldn’t surprise me if you shift down sixteen bits and find that all your pointers have the same values in the shifted-down bits and you get just as many hash collisions as before. (oh and if code uses SIMD instructions, it’s common to just align all heap allocations by sixteen bytes because you can get segfaults for doing certain SIMD instructions on unaligned data. So in my world all pointers are sixteen byte aligned and you are losing one more bit that you have to make up for with just that single shift)
Another pattern that would give you problems is if you have two values and you combine them in the hash. For example I once had a grid of data, and I used the X and Y coordinate of the cell as the hash: The X coordinate was in the lower 32 bits, the Y coordinate was in the upper 32 bits. That immediately gives you problems if you just do a single shift by sixteen. Because half the data is 32 bits over, not 16 bits over, so now your table has to be at least size 65536 before you start using the Y coordinate at all, and you’re getting a massive number of hash collisions before that. Let’s say I compress things so that the X coordinate is in the lower 16 bits and the Y coordinate is in the next 16 bits. Now you get a problem where all diagonal coordinates like (1, 1) hash to the same value, because the xor makes the result zero. So the next thing to try would be to have a more complicated hash function on the client side so that the X and Y coordinate contribute in a less predictable pattern. (maybe use FNV1 hash like Dinkumware) But now you’re even slower, just because you had to work around a problem where the hash table had a bad way to map from hash values to slots. (and you’re still paying the cost for that on top of the cost of FNV1)
You may say that that is a bit of a constructed example (it’s a real example though, honest) but even if you never do this specific thing, there is a very common pattern of having IDs combined of several different bits of information. Like maybe the lowest 32 bits of your ID are just an incrementing counter, the next 8 bits of the ID indicate a type, the next 16 bits have different meaning depending on the type, and the top 8 bits indicate a sort order. I’m sure you have seen constructions like that. And I’m sure you can immediately see how those break with the Java method. (like any change to the “different meaning” bits will just get ignored if your hash table is small)
Plus it also suffers from the same problem as the C++ code where it’s written for a 32 bit platform, and for a 64 bit platform you’d want to do more work to use the whole hash. And if you change it so that it does a second shift and a second xor, it’s already slower than Fibonacci hashing. So we’d have to be more clever to adapt it to 64 bits, otherwise we might as well use Fibonacci hashing. (more cleverness meaning you’d have to take advantage of instruction level parallelism somehow, which neither the Java code nor the C++ code does)
All that being said I still think the path of “xor + shift” is worth investigating. I would just start off by looking into Knuth’s third hash function, because he actually proves that that has good properties.
And finally, I actually think that the two examples you posted are perfect examples of how much of a shame it is that the world forgot about Fibonacci Hashing. People saw that prime number integer modulo is slow, so they use power of two integer modulo. But now they get lots of problems so they try to deal with those problems, but they’re improvising and it ends up bad or too slow. They should have just used Fibonacci hashing. It’s simply the best trade-off for this problem.
I don’t know what you mean by Knuth’s third hash function, but in the hardware world, building hash tables with randomly-generated CRC-like matrices is very standard and those hash functions have a lot of great properties. The problem is that those don’t translate well to Intel instructions. The CRC instructions don’t mix bits well. If you’re taking the hit to use AVX/AVX2 instructions, you can do something similar to a hardware hash table and be very happy, but the instruction path might be a little long through SSE instructions only (although still full-throughput unlike integer modulo), and the cost is going to grow as the hash table gets bigger. That being said, I’m not all that familiar with how people tend to handle the issues related to power of 2 hashing, so there’s a chance that even doing the “slow” thing is fast enough.
Great article as always, and thank you for all that useful information you provide!
Now at the risk of being nitpicky (but I also write that as reference for whoever will read this thread in the future), I think your assumptions regarding Java are not correct. Although Java objects are indeed 8-byte aligned in the JVM heap, you never manipulate the actual addresses in (non-native) Java code, let alone when hashing object references. There seems to be a widespread idea that Object’s default hashCode implementation (the so-called “identity hashcode”) uses the address of the instance, but it normally does not, for the very good reason that the JVM may move objects around during GC sweeps (and that as you point out, it’s not a very good hash anyway since it only uses a limited number of actual bits). This article [https://srvaroa.github.io/jvm/java/openjdk/biased-locking/2017/01/30/hashCode.html] explains what really happens in OpenJDK’s HotSpot for instance, and it is quite involved and has evolved across different Java versions from outright random numbers to a hash based on the state of the current thread. The point is, the JDK HashMap implementation, with its xorshifting and power-of-2 tables actually work really well with identity hashcodes. Now of course, if instead of objects, you hash scalars which tend to be not-so-large multiples of 8/16/32…, then your point becomes valid again.
Awesome writeup! Thanks for sharing
Maths in Nature
How is multiplication by 11400714819323198485 different from multiplication by a large prime number?
I don’t know if it matters here whether the number is prime or not. The properties that you want for multiplicative hashing are different like, “there shouldn’t be too many zero bits in a row.” Prime numbers may or may not have that property.
The one thing that you definitely need is that the constant comes from a division of by an irrational number. If you accidentally can get there by dividing by an integer or by a rational number, then when you wrap around you will eventually get back to the starting position, and you won’t use all the slots in the hash table. For example here is a large prime that would be a terrible choice: 11068046444225730979. I found that number by entering “nearestprime(2^64/(5/3))” in Wolfram Alpha. This number comes from a division by a rational number and will not visit all the slots in your hash table as it wraps around. I just tried this for a table of size 8, and it only visits slot 0, 1, 3, 4 and 6. For larger tables it’s even more wasteful.
by an irrational number. If you accidentally can get there by dividing by an integer or by a rational number, then when you wrap around you will eventually get back to the starting position, and you won’t use all the slots in the hash table. For example here is a large prime that would be a terrible choice: 11068046444225730979. I found that number by entering “nearestprime(2^64/(5/3))” in Wolfram Alpha. This number comes from a division by a rational number and will not visit all the slots in your hash table as it wraps around. I just tried this for a table of size 8, and it only visits slot 0, 1, 3, 4 and 6. For larger tables it’s even more wasteful.
I was playing around with different constants before posting the blog post, but I only ever found bad constants, (and found lots of new ways that constants can be bad) so I left that part out of the text.
Taking the lowest bits, instead of the highest bits, of the multiplication provides an even distribution.
The GCD of a prime number other than 2 and 2^N is 1, which means it outputs the whole permutation as it wraps around the powers of 2.
Taking the lowest bits gives the remainder of dividing by 2^K.
#include
#include
int main() {
const uint64_t m = 11068046444225730979llu; // prime
//const uint64_t m = 18446744073709551629llu; // nearest prime 2^64
//const uint64_t m = 3; // smallest prime other than 2
#define K 1024
int count[K] = {};
for(uint64_t i=0; i<100*K; i++) {
uint64_t h = (i*m) & (K-1);
printf("%ld\n", h);
count[h]++;
}
printf("\n");
for(size_t i=0; i<K; i++) {
printf("%d\n", count[i]);
}
return 0;
}
I think that function is discarding the upper bits. In this loop header:
for(uint64_t i=0; i<100*K; i++)
{
// …
}
Try doing larger step sizes. For example doing this:
uint64_t step_size = 1024 * 1024;
for(uint64_t i = 0; i < 100 * K * step_size; i += step_size)
{
// …
}
Now they will all be mapped to zero because now we're iterating through the upper bits, and that hash function will discard the upper bits.
Well, but there is no such thing as step_size=1024*1024 in my codes because I always try to keep the randomness in the lower bits or even better to keep the randomness uniformly distributed over all bits of the 64-bit integer.
Hi! Any chance you can upload your benchmarks and also your implementation of google’s new hash table?
Yes, sorry, it’s still in the plans. I just got excited by Fibonacci hashing, so that took priority.
You wrote: “the number 11400714819323198486 is closer but we don’t want multiples of two because that would throw away one bit”
Note: This bit which is lost is used only if you have a bucket size of 2^64 (which is unrealistic). In all other cases where you have a bucket size of 2^n (with n<64) you throw away this bit anyhow by the right shift.
You’re actually losing the top-most bit of the input hash. Because if you multiply the top-most bit by anything other than 1, you will overflow and then lose it after truncation. So the 1 bit has to be set in the magic constant. And the top-most bit of the input hash is used for any number of buckets, not just for 2^64, because we shift the result down after the multiplication.
Yes you are right. Thank you for the clarification.
Since Fibonacci multiples have essentially random values for the lower bits, I wonder if you can break up any remaining ill conditioned patterns by XOR-ing the result of the multiplication with the input value itself. Intuitively, it should combine the strong hashing power of the multiplication with the excellent spreading you would otherwise see for a Fibonacci pattern mapped 1:1 in a power of 2 sized table.
I think that might work, but you’re adding two instructions to the critical path there. You have to do the xor, and then you have to do another binary and to get rid of any bits that are too high. The other problem with that approach is that you’re not using the top-bits more. You are only using the bottom bits more. So I think you’re only going to gain a little at the cost of making all lookups more expensive.
I think it’s just a single instruction, since you are already clamping the upper bits to fit the table. For a power of 2 table, something like this:
return ((hash * 11400714819323198485llu) ^ hash) >> 54;
Depending on the exact hardware architecture, an extra XOR could come almost free compared with a 64 bit multiplication and barrel shift. The sole purpose of this is to gain generality over your algorithm in the face of “multiple of N” data, where N is variable and performance suddenly drops for magic values of N.
Oups, I see now that won’t work since your shifting out the lower bits. Indeed, it needs two extra instruction, at which point your shift-xor scheme before multiplication is probably preferable, with a strong avalanche to other bits.
Yeah I think if you do the xor before the shift, you get a problem with the top-most bit. That bit will just be xor-ed out. So the contribution of the top-most bit of the input would disappear.
Great article. Glad my comment was useful!
I’ve read Knuth’s “Sorting and Searching” from cover to cover a few times, always on the lookout for new/interesting algorithms.
(“new” meaning algorithms or methods that modern software engineers have ignored or forgotten)
Correct me if I’m mistaken, but wouldn’t any of the irrational square roots of whole numbers work just as well as phi in this case? By being an irrational number, the same property of distributing petals around a circle without overlapping should persist. Maybe using one of these would resolve the problem of certain numbers not working well with the Fibonacci hash.
Only if you disregard rounding, I believe. The beauty of Fibonacci hashing is that with incrementing inputs, the output will always fall in the largest open interval (ie. as far as possible from any earlier element).
Yes, any irrational number will wrap around without getting back to the starting point. And I actually spent a good amount of time searching for a replacement number that has fewer problematic numbers.
But I just found lots of ways to break multiplicative hashing. Like if there are too many zero bits in the number, that causes problems. Or you try a number and it’s not obviously bad, but some of your benchmarks suddenly run 10% slower, indicating that there are more hash collisions, and it’s hard to find out where they come from.
The golden ratio however did well in all my benchmarks. It’s only when you stop using it that you discover how many problems you run into, and how careful the choice has to be.
I still think there are other good numbers out there, but I don’t know how to find them. But it wouldn’t surprise me if there was a better choice out there than the golden ratio.
While I’m not sure how to find them either, I think I have a quick test to discard most bad ones. My old criteria were:
– hex representation doesn’t contain 0 or f,
– popcount of both 32-bit halves is 16 and
– must be a prime number.
Pick a random number and roughly one in 10k will match all criteria above. Maybe slightly weaker criteria would also be ok, you want roughly half of all bits to be 1 while my criteria enforce exactly half – and do that for both halves of the multiplier. Similar for the hex representation, you want to avoid long sequences of identical bits. Excluding 0 and f limits sequences to 6 identical bits, though not necessarily in the most mathematically sound way.
Another important detail that I missed in the past is:
– the multiplicative inverse shouldn’t be a common number like 3 or 5.
My hunch is that enforcing the same criteria as above for the multiplicative inverse would be a good choice. But I have to spend more time on that.
You golden-ratio-based multiplier, 0x9E3779B97F4A7C15, is pretty close. I see one F and one sequence of 7 1-bits, popcount is 38. So you missed my criteria, but not by much. Might say more about my criteria being overly pessimistic than about your constant being bad.
The golden ratio works well, for this job, because it’s particularly hard to approximate well with a ratio of whole numbers. Successive entries in Fibonacci’s sequence are as good as you’ll get, and even that sequence, f(i+1)/f(i) for successive i, converges slowly relative to good rational approximations to various other irrationals. Your problem sequences come where you look at a succession of values that are multiples of a good denominator for a rational approximation.
You’re using hash(x) = (x*k)%N with k = (r*M)%M for some irrational r, M = 2^64 and N as some smaller power of two. If it weren’t for rounding, hash(x) would be (x*r*M)%N and, for some rational m/n approximation to r, hash(i*n) is close to (i*m*M)%N, which is zero; the “close to” difference is (i*(n*r -m)*M)%N and some rounding errors; if m/n is a good approximation, this is small and you get the zeros you saw with larger Fibonacci numbers. At least, that’s what I think is happening …
One way to consider rational approximation of an irrational is to split the irrational into whole number and a fractional part, then apply the same method to approximate the fractional part; go a few steps, approximate by a whole number, then unroll back to where you started. Thus, for pi we get pi = 3.1415…, 1/(pi – 3) = 7.0625…, 1/(1/(pi-3) -7) = 15.99…, let’s call that 16; so 1/16 = 1/(pi-3) -7, pi = 3 +1/(7 +1/16) = 3 +16/(16*7 +1) = 3 +16/113, good to three parts in ten million; and I only went a few steps in. One can slightly improve this by, rather than a whole-and-fractional split, using the nearest whole number and a +/- fractional error, so that the error is never more than a half (where 15.99… would have had error .99…) and the whole number is never (after the first step) less than two. This approach truncates a “continued fraction” approximation to the irrational, pi = 3 +1/(7 +1/(16 -1/(294 -1/(3 -1/…)))) in order to obtain a good rational approximation.
You can do the same with the golden ratio, of course. It’s the solution to x*x = x +1, so I can tell you right away that x = 1 +1/x = 1 +1/(1 +1/x) = 1 +1/(1 +1/(1 +1/(1 +1/…))). That’s using the simple whole+fraction split; if we allow negatives, we have x -1 = 1/x, so x/(x -1) = x*x = x +1; with q = 1/(2 -x) = 1/(1 -1/x) = x/(x -1) = x +1, we get 1/(3 -q) = 1/(2 -x) = q, whence q = 3 -1/q = 3 -1/(3 -1/(3 -…)) and x = 2 -1/q = 2 -1/(3 -1/(3 -1/(3 -1/…))) and it’s threes all the way down. This means you never get a nice big number in the sequence (like our sudden leap to 294 in pi’s continued fraction), for which the 1/… you’ve got to add to it or subtract from it is a small fractional difference, making that a good place to truncate. So rational approximations to the golden ratio improve painfully slowly – which is a PITA if you want a good rational approximation, but a blessing when you’re trying to pick an irrational to use in your multiplicative hashing. When we truncate 1 +1/(1 +1/…) before successive +s, we get 1/1, 2/1, 3/2, 5/3, 8/5, 13/8, …, the ratios of successive Fibonacci numbers. Truncating 2 -1/(3 -1/(3 -…)) before successive -s, we get 2/1, 5/3, 13/8, 34/21, …, selecting every second entry from the previous sequence; allowing subtraction doubles our speed of refinement, but it’s still painfully slow.
So can we find something more pathological than the golden ratio ? Well, the only credible candidate is 2 +1/(2 +1/(2 +1/…)) = z = 2 +1/z so 1 = z*z -2*z = (z -1)^2 -1 and z -1 = sqrt(2) so z = 1 +sqrt(2) = 1/(sqrt(2) -1). So maybe give that a try – obviously, you’ll be dividing by it, using r = sqrt(2) -1 in my analysis above. I’d be interested to know how well it fares as a hash ;^)
Sorry – I said: “split the irrational into whole number and a fractional part, then apply the same method to approximate the fractional part” but meant … apply the same method to approximate the *inverse of the* fractional part.
Note that successive truncations of 2 +1/(2 +1/(2 +…)) are 2, 5/2, 12/5, 29/12, 70/29, 169/70, 408/169, … so it’s the denominators showing up here that are apt to give trouble for 2^64 *(sqrt(2) -1)
Curious to why all implementations have such an obvious knee in the graph.
It’s where the table is too big to fit entirely in L3 cache. At that point you start getting more and more cache misses, and those are really slow.
I should have thought of that…
The article *assumes* that integer division by a prime is slower than integer multiplication followed by the shift. This is not necessarily true.
Can you elaborate on that? The claim for integer division being slow comes from measurements, not assumptions. But I also wouldn’t be surprised if there were faster ways of doing the division. I know of libdivide, but that’s slower than Fibonacci hashing. But if you know of another way to make it fast, I would be very interested.
I think they are referring to some clever transformations a compiler can make to avoid divisions, for example: https://godbolt.org/g/7hfX19
In that case it is very obvious that it’s slower than a multiply + shift, but there might be “good” primes that you can calculate division (mod 2^64) quite fast for.
“Can you elaborate on that? The claim for integer division being slow comes from measurements, not assumptions.”
Looks like you’ve measured the performance of modulo by a variable (i.e. a number unknown at compile time) when you should be measuring the performance of modulo by a constant.
As others have said, modulo by a constant is optimised into much faster code by any decent compiler. I expect if you measure it you will find that there is no justification for the alternatives.
Modulo by a constant is what I used before I switched to Fibonacci hashing. It was slower. If there are “good” primes that can do a modulo quickly, I don’t know how to find them. (there is also a risk that those prime numbers might be bad for hash tables, which you can only really figure out by measuring a couple of bad patterns)
Jon what do you mean when you say this:
“As others have said, modulo by a constant is optimised into much faster code by any decent compiler. I expect if you measure it you will find that there is no justification for the alternatives.”
I have measured it and it wasn’t faster.
I agree with Malte. “good primes” are precisely good because they are of low complexity, which makes them “bad primes” for hashing.
Modulo constant is going to reduce to around two multiplications, and some shifts and adds. But most importantly hash table sizes are not fixed, you’d need to force compilation of reduction with all possible moduli, maybe like this: https://gcc.godbolt.org/z/4T6ZaD
I can easily imagine this being slower even if you have to emulate a 64 bit multiplication with three 32 bit multiplications and 4 add/sub because of smaller code size at a similar computational effort.
You can accelerate division by computing an analog to the inverse of a number with the Newton-Raphson method. To compute the division you multiply the inverse and the number you want to divide and then take the high bits. The result is potentially 1 less than the division you wanted, so you check for that and you are done. If you store the inverse and if the division is going to be repeated more than three times it should already be worth it according to my benchmarks. Computing and applying the inverse takes around 2.7 times more than the hardware division, but the hardware division takes 13.3 times longer than just applying the inverse, that is when the divisor is momentarily constant.
Well I’m not saying that you should do that, because you could just as well be using fastrange, it has the same overhead, the same operations even. But if you wanted to use modulo reduction then this is the way to go in my opinion.
There are definitely use cases where you need to be at least somewhat robust to adversarial input — eg, in a Javascript implementation that’s going to be used to run arbitrary code on the Web. Then I think you need the property that a pathological input won’t be problematic on all machines, only a random subset. I believe the standard fix is to use a hash function (in the traditional sense, not the big -> tablesize mapping) that incorporates a random seed.
I guess you could just declare this to be the problem of the hash function whenever the user controls the input. I don’t know if it’s enough to xor with the seed in between the hash and range-reducing steps? When using a Fibonacci reduction, I mean. (You could think of that as either the final step of the hash function, or the initial step of the reduction, depending on how much you trust the users to choose appropriate hash functions depending on where their input comes from.)
I don’t think this problem is restricted to directly web-exposed code, either. You don’t want someone to be able to DOS you just by picking a whole bunch of awkward user names, for example. Databases probably need to worry about this too.
Yes, that is a great point because none of my hash tables handle this right now. I am also not sure where to handle this. My first thought would be to generate a random number on hash table creation, and to always xor that with the result of the hash function.(just before the Fibonacci hashing) But I honestly don’t know if that’s good enough, and I wouldn’t want to make a change like that unless I know it’s good, and unless I can test it. And I don’t work in an environment where I can test it, so for now I don’t do this. I think it’s better to obviously not handle this than it is to pretend to handle it with a bad solution.
I might just use Google’s solution when they open source their hash table. They xor the address of the bucket memory into the hash value. If that is good enough for them, it’s good enough for me. (You need to have ASLR enabled)
As far as I know, randomizing isn’t sufficient, because it’s too easy to leak the seed inadvertedly (or simply try a bunch of inserts, observe which of them that take longer time, repeat, and tada, you have a lot ot them and can do an attack). I thought Robin Hood hashing was regarded a more robust solution than randomizing, but I might be wrong.
Btw prime bucket sizes could also be improved.
As you see here:
https://godbolt.org/g/LZCtwi
compilers replace slow div instruction with mix of mul shr, lea, sub.
Unfortunately IDK the math behind it so I would not know how to produce C++ function that only depends on few params(for example as you can see sometimes codegen uses sub, sometimes it does not).
Yes, my old default (before Fibonacci hashing) was an improved version of integer modulo. And you can still use it by using the prime_number_hash_policy with my hash tables. The fastest version I have found of that is actually to use libdivide. (https://libdivide.com) But the reason why that wasn’t my default choice was that it caused the code size of my find() function to grow, and that made inlining less likely, and losing inlining was a bigger cost than the speedup from using libdivide. So I used the custom solution that’s still in there.
Fibonacci hashing is still faster though, and I like that it breaks up sequential numbers.
regarding prime_number_hash_policy
I am not surprised it is slow since it can not be inlined(in theory it can but function ptr makes that hard).
What I was thinking about is not having dozen of functions and adjusting a pointer but having one function and adjusting arguments.
But like I said IDK the recipe that compilers use for optimization…
Still I managed to find 5 primes that give nice form of optimized code(all 5 primes have same sequence of asm instructions with 2 diff constants) that could be used to implement as a simple function with 2 arguments(beside input hash).
https://godbolt.org/g/97WZmn
If you want you could test it and see if it performs better.
regarding inlining:
maybe you could try POGO, in theory every program that cares about performance will use it anyway. 🙂
To replace division with multiplication, you can look up the extended euclidian algorithm. Or use this function:
static uint64_t inverse(uint64_t m)
{
uint64_t t, r, newt, newr, q, tmp;
r = m; newr = -m;
t = 1; newt = -1;
while (newr) {
q = r / newr;
tmp = newr; newr = r – q * newr; r = tmp;
tmp = newt; newt = t – q * newt; t = tmp;
}
return t;
}
Finds the multiplicative inverse for any odd 64bit number.
While at it, here is a fun bit of brute-force math:
uint64_t mstep = -1ull;
for (int i = 1; i <= 1 << 16; i++) {
uint64_t step = i * 0x9E3779B97F4A7C15ull;
uint64_t astep = step;
if (-astep astep) {
printf(“%8d: %16lx %16lx %16lx\n”, i, step, astep, mstep);
mstep = astep;
}
}
This just tries every increment and prints it out if the step for fibonacci hashing would be worse than for any smaller increment. Some of the numbers printed might seem familiar.
I suppose you could also use this code to search for a better multiplier. For example 0x6659948fa40e609bull appears better for most increments.
@Joern
thank you…
but why do compilers use mul and shift if they could just use mul(if I understand you correctly)?
@Joern
I do not understand what you mean by “multiplicative inverse”. I thought that multiplicative inverse was the reciprocal of a number, so it could not be an integer. Am I missing something?
Modular arithmetic makes a difference. If you multiply 0x9e3779b97f4a7c15 by 0xf1de83e19937733d, you get 0x957bbf35006ed6770000000000000001, a large 128bit number. If you only look at the low 64 bits, you get 1. If you only consider the remainder after dividing by 2^64 (as computers do), the product is 1 and each of the two factors is the inverse of the other.
Every odd number has a multiplicative inverse in mod(2^64). Even number can be “made odd” by shifting, so replacing division by 6 involves an inverse for 3 and a shift.
I’m a couple months late, but I just wanted to say that I agree with everything that Sebastian Sylvan said. In a nutshell, a hash table should take the output of a user-supplied hash function, “mix” the hash using a robust integer permutation, and then use fastrange to map the result into the table. If you use a permutation rather than a general function for the mixing step, you are guaranteed no collisions. That means that as long as your user-supplied hash function has no spurious collisions, the input to fastrange will have no collisions either. So the best possible user-supplied hash function for integers is in fact the identity function: it is cheap (free) and has no collisions. As for the mixing permutation, I used to use a reduced-round version of the 32-bit Speck block cipher, but I recently switched to the 2-round permutation described in https://github.com/skeeto/hash-prospector, and it’s much faster and statistically just as good for my purposes. (I hear the Murmur3 finalizer also works quite well for this.)
PS It makes no sense to use xxHash as a mixing function. 1) it is not a permutation, so it can have collisions, and 2) it is a byte-at-a-time hash function, designed for variable-length strings, not fixed-width integers.
PPS Robin Hood hashing isn’t quite the final word on linear probing. There’s a couple of other linear probing variants I’m currently benchmarking, and one of them is clearly superior to Robin Hood (and predates it by over 20 years)…
Carry less multiplication and xor-ing the resulting two n-bit blocks to produce the hash is a permutation that also spreads the entropy in the input very evenly. On a modern CPU this will only cost about 3 to 4 cycles in addition to a latency to 4 to 7 cycles. Meaning it will be almost as fast as the fibonacci hash.
#include // compile with -mpclmul
uint64_t const clmul_circ(const uint64_t& a,const uint64_t& b){
__m128i ma{(const int64_t)(a),0ull};
__m128i mb{(const int64_t)(b),0ull};
auto t = _mm_clmulepi64_si128(ma,mb,0);
return t[0]^t[1];
}
uint64_t const distribute(const uint64_t& a){
return clmul_circ(a,15112557877901478707ul); // any odious integer will do
}
One could go one step further and at the cost of two more carry-less operations and four xor’s one could construct a galois field by reducing with an irreducible polynomial like in AES-GCM
Click to access carry-less-multiplication-instruction-in-gcm-mode-paper.pdf
I don’t think much would be gained by doing that though.
Turns out clmul_circ is not mixing well enough, I ended up doing:
uint64_t const gfmul64(const uint64_t& i,const uint64_t& j){
__m128i I{};I[0]^=i;
__m128i J{};J[0]^=j;
__m128i M{};M[0]^=0xb000000000000000ull;
__m128i X = _mm_clmulepi64_si128(I,J,0);
__m128i A = _mm_clmulepi64_si128(X,M,0);
__m128i B = _mm_clmulepi64_si128(A,M,0);
return A[0]^A[1]^B[1]^X[0]^X[1];
}
where clmul is fast enough, and rotate_left(h*c1,21)*c1 where it is not, so very similar to what you did, but when rotating instead of shifting one does retain the injective property of the hash.
Hello Malte! Thank you for the very informative post and for bringing up much interesting discussions. It turns out the technique is the the same as the once used in the Linux kernel for hashing pointer address values since 2016:
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/include/linux/hash.h?h=v5.11.7#n37
The header’s date says 2002, but before 2016 they used a prime factor which turned out not so well-conditioned. But the word “prime” in the macro stuck, hence the comments and compatibility macros defined in the beginning. So indeed we keep on rediscovering the technique, and it’s right now being used whenever Linux runs ^^
Curiously, they use the modular factor for (1 – φ) instead of φ as the multiplier, and the code comment suggests that (1 – φ) “is very slightly easier to multiply by”. I guess the reason is that the value is the smaller one, and the most significant nibble of the (1 – φ) factor is 0x6 instead of 0x9, therefore one bit shorter than the φ factor when written out as binary. Maybe this could have made it “slightly easier to multiply by” on platforms that lack native hardware support for 32/64-bit multiplication? Or maybe it’s just that the 64-bit factor ends in 0xB, so that they could spell out the literal as “0x…Bull” in the C code 🙂
I personally find the multiplicative hash by φ or (1 – φ) very effective when you want to hash pointer addresses into a small number of slots. Address values are not arbitrary, for the most significant bits tend to be fixed by the segment, and the least significant bits tend to be multiples of some common factors dictated by alignment requirements. The informative bits are likely in the middle, but there they could still be subject to patterns created by particularities of the memory allocator. By scrambling with a multiplier and taking the highest bits, these patterning effects tend to be reduced.
There’s another potentially useful technique if we want the the hash to be perfect or near-perfect for a small and fixed collection of input values: rotate first, then hash by golden ratio. The “ideal” number of bits to rotate by can be figured out by trial and error at setup time, provided that the input collection is small and the initial table leaves enough empty slots to allow for some slack. For instance, if we begin with 8 unique inputs and make the initial table size 16, I think we’re guaranteed to find a rotation-distance between 0 and 63 that put the 8 inputs into distinct slots among the 16 total. I imagine this as rotating the inputs such that their informative bits are juggled out of the places not adequately scrambled by the Fibonacci hash and put into its sweet spots, without losing any bit. To reuse one of your examples, the multiple of 144 (a Fibonacci number) by any number in [1..8] maps to 7 identically if we just take the highest 3 bits of the hash, but if we rotate the input by 3 bits first, the outputs nicely distribute to unique values in [0..7].
If the hardware supports it, the rotation arithmetic compiles down to one instruction. Compared with shift-and-xor, it saves one arithmetic but adds one load. I find it helpful for one specific job: building a small lookup table or “frozenset” for fixed constant pointers. Once built, for any non-zero input it answers the question “is this input among the elements in the set?” in constant time using no branching. If the input is also guaranteed to be a member and we want to do lookup, the keys don’t need to be stored.
Anyway, thank you so much for the post! I hope you’re doing well!
You are not guaranteed to find that rotation at all. The probability for success is 14750191/16777216 .
For each rotation. For 64 rotations, if they are independent, the probability for failure is 1.806797088433464E-59 . We can find a counter example by making some rotations degenerate by randomly choosing n and then shifting it to the different bits.
n=rand(256);{n<<(3*0),n<<(8*1),n<<(8*2),n<<(8*3),...,n<<(8*7)}
This will mean only 8 out of the 64 rotations can be independent. Lowering the chance for chance for success to 99.8% .
Hi! Thanks for the correction; I should have been more precise 🙂 Since the comments don’t nest I’m replying to your last message actually. As I understand it, if the inputs in this case are rotationally symmetric (is that what you mean?), rotation of course fails to adequately break the symmetry. As an extreme example, if the inputs are the 64 integers with the “1” bit on each of the 64 places, the rotation step is totally useless. For this particular case, we’d have to enlarge the table size to 1024 (if working with powers of 2) when those keys start to map into distinct slots, which is super (16x) wasteful — compared to perfect and minimal hash function (the logarithm will do for this instance). Fortunately for my purpose (hashing pointers to static variables or long-living objects allocated in some pool), the memory allocator is not my adversary, hopefully!. The keys are clumped in some range but otherwise without “bad patterns”. In the end I tend to get away with it without enlarging the table by too much ^^
Even so, I can only use the rotation trick for small tables (typically < 16) — anything larger would have required a real perfect hash function or another data structure for efficient lookup.
But back to Malte’s original post, where the purpose is to map a real hash code into slots. I don’t know if an additional rotation step could help alleviating some of the “bad patterns” such as multiples of a Fibonacci number. I guess it may not worth the overhead except for some very specific cases.
P.S. when you wrote “The probability for success is 14750191/16777216”, how do you mean “probability”, and what is the random space? I’m afraid I’m not on the same page with you. How did you derive these numbers? Thanks!
n is the number of items with random hashes in the range [0,m], m is the number of slots, the probability for a collision is (m-1)/m(m-2)/m…(m-n+1)/m which is approximately exp(-n(n-1)/(2*m)) . The collisions scale inversely with the number of slots but to the square with the number of items.
In your scheme you could forgo the rotations and just try different uneven integer multiples, this would give you a larger space to search from. But it would still not get you far. You should look at more advanced perfect hashing schemes. Or, if you just have 8 values, take just a flat array, it’s faster than you think, testing 8 values is very quick. And for more than that there’s nothing wrong with a proper hash table.
we essentially get new random numbers in the range [0,15) for each rotation. The second number needs to fall in any of the 15 free slots out of 16 total, the third needs to fall in any of the 14 free slots out of 16 total and so on.
This article is quite misleading. Also the world did not forget about fibonacci/golden ratio/multiplicative hashing, but some people choose not to use it, because this method with power of 2 hash table sizes, results in too many collisions. The best method is to use a hash table with a prime number. Yes modulus arithmetic is a little bit slower, but you will gain performance by not having to deal with a large number of collisions. There is no such thing as free lunch and I’m yet to see a power of 2 hashing function that has comparable collision rate to the one with a prime number and modulus arithmetic. Please stop spreading misinformation.
Yes the title is slightly exaggerated to generate clicks. He showed you the number of collisions observed and powers of two do not lead to more collisions than any other hash table size, if you apply a good hash function. When the hash function has a uniform distribution you can use whatever modulus you like, and also other ways of range reduction like
fastrangetoo.Can you please show me a hash function where what you say is true for integer values like pointers that are aligned on 8-byte boundary – 8, 16, 24, 32, etc.
mul_hash(uint64_t start, uint64_t step):
uint64_t buckets;
uint64_t buckets_len = 4194304; / Power of 2 number: 2^22 /
uint64_t buckets_len_log2 = 22;
const uint64_t gr = UINT64_C(11400714819323198485); / Golden ratio */
for (i = 0, n = start; i < buckets_len/2; i++, n += step)
{
hcode = n;
index = (hcode * gr) >> (64 – buckets_len_log2);
}
mod_hash(uint64_t start, uint64_t step):
uint64_t buckets;
uint64_t buckets_len = 4194301; / Prime number close to 2^22 */
for (i = 0, n = start; i < buckets_len/2; i++, n += step)
{
hcode = n;
index = hcode % buckets_len;
}
And the results are:
mul_hash: start=8, step=8, time=15.62 msec, coll_cnt=100957
mul_hash: start=64, step=64, time=30.61 msec, coll_cnt=289511
mod_hash: start=8, step=8, time=24.38 msec, coll_cnt=0
mod_hash: start=64, step=64, time=35.54 msec, coll_cnt=0
The multiplicative hashing (as originally suggested by Knuth) results in around 100K and 289K collisions, while modulus hashing results in 0 collisions. If you change “hcode = n” to any chosen hash function that returns 64-bit hash code based on value “n”, you still end up with huge number of collisions, and this is with a hash table at 50% load. I’ll take modulus hashing any time of the day – simple and effective.
Have a look at my answer on stackoverflow here:
https://stackoverflow.com/questions/664014/what-integer-hash-function-are-good-that-accepts-an-integer-hash-key/57556517#57556517
Or use splitmix64:
uint64_t hash(uint64_t x) { x = (x ^ (x >> 30)) * UINT64_C(0xbf58476d1ce4e5b9); x = (x ^ (x >> 27)) * UINT64_C(0x94d049bb133111eb); x = x ^ (x >> 31); return x; }For a well distributed hash function. But then you’ll say this is two multiplications, and you’d be correct. But even one multiplication is often sufficient, and then we have arrived exactly where Malte had.
Actually the collision rate is even worse, as I copied and pasted the wrong lines of text
mul_hash: start=8, step=8, time=15.81 msec, coll_cnt=201861
mul_hash: start=64, step=64, time=30.76 msec, coll_cnt=579039
mod_hash: start=8, step=8, time=23.89 msec, coll_cnt=0
mod_hash: start=64, step=64, time=35.34 msec, coll_cnt=0
It doesn’t matter what hash function you use, when it comes to multiplicative hashing for mapping hash code to hash table index, you will get large number of collisions for certain data sets. Here is a link to my code, plug in whatever hash function you like:
https://drive.google.com/file/d/1Qphu8JfZDZ9CBfIxk5jqAT8fqviPjBRv/view
Any hash function will give large amounts of collision for “certain data sets”. For the very specific case of a super-dense range of pointers whose range happens to fit exactly into the hash table, prime modulo will do much better than a multiplicative hash. Likewise, if you have modulo with a prime p, hashing integers that are exactly p apart will give you catastrophic amounts of collisions. But if either is a very important case for you, perhaps you shouldn’t be using hashing in the first place.
I could not have said it better myself, Steinar H. Gunderson. I just want to add one thing. If you have well distributed values and a 50% load factor the expected number of collisions is about 10.6% with respect to the number of buckets (equivalent to 21.3% w.r.t number of elements).
https://stackoverflow.com/questions/9104504/expected-number-of-hash-collisions#11362027
If you think you can do better you might be able to create a perfect hash function specifically for your data.
I think you’re missing a point. Quite often input data is not completely random and follows a specific pattern. A good hash table should handle a variety of different input data efficiently. Using modulus arithmetic with a prime number will give you the least number of collisions with many different patterns. It just works for all the usual cases. There are many patterns where using power of 2 hash table is quite sub-optimal due to high number of collisions.
Modulo will only have that (very nice!) property if you are hashing using the identity function (ie. no hash at all), which is a dangerous game to play.
Note that it’s not really the case that multiplicative hashing is doing particularly bad in this case; it’s doing fairly well evenly across almost all inputs. It’s just that the identity function + modulo does extremely well in this one specific case.
Your benchmark is misleading, by the way; you’re doing the modulo by a constant, which means the compiler can rewrite it into multiplicative form. This is only really possible if your hash table has a fixed number of buckets; otherwise, for non-constant, you will either have to have a real division, oor something like libdivide and/or a huge switch/case (like ska_flat_map). Changing that to a more universally usable variant is going to increase your (already big!) speed penalty, and/or code size.
You have access to my code, so you can make whatever changes you like that inhibit compiler optimizations and see for yourself. I tried various things and not noticed much difference on my hardware. Using identity function with prime hash table size is the key method that gives low collision rates. Depending on the hardware, modulus arithmetic can be relatively quick. There are other things happening in tandem and will cause CPU pipeline stalls, no matter how quick your indexing function is. In my experience, for non-random integer types that increase sequentially (file descriptors, pointer values, etc), using prime hash table sizes gives the best performance due to very low collision rates.
I actually think the benchmark results are OK. Sure, at 2^22 = 4 million pointers (integers with stride 8) you start getting a few collisions. If you try the same test with 2^21 pointers, you get zero collisions.
If you try it with an actual hash function, you get more collisions: Roughly the 10% that 1yk0s mentioned, when I tried with std::_Hash_impl::hash(). (not officially supported, but it was an easy choice)
I still think on average this is pretty good and the performance benefits over integer modulo is still worth it. Going from 16ms to 24ms is not a small difference. (plus, you don’t quite measure the overhead of modulo correctly because presumably you won’t be using only one known prime number. You want to allow tables of different sizes. The compiler has a harder time optimizing when there are multiple possible constants)
The goal isn’t zero collisions. You won’t get that on any data that’s not regularly spaced. The goal is few collisions for all common patterns. And I mention one common pattern in the article where prime number modulo has problems: mostly sequential numbers. If your numbers are mostly sequential, meaning 1,2,3,4,…,10000, except occasionally you have other numbers in there like -20 or 2^22 or 2^22+4, that behaves really badly in prime number modulo, because the hash table will be densely packed and on collisions you have to search for a long time to find a free slot. Fibonacci hashing will spread these out, which gives you plenty of space to cheaply resolve hash collisions.
About the claim that the slower instructions are worth it because you get fewer collisions: Maybe. I’d like to see it on real data. Intuitively it shouldn’t be worth it because by far the most common case is that you immediately find the item you’re looking for in a hash table, so you want to optimize for that and use the fastest instructions possible on the happy path.
Not quite, the results speak for themselves. Inserting 2 million integers into a hash table with 4 million buckets (only 50% usage) and you get:
Modulus hashing using identity function: 0 collisions with most sequential numbers.
Multiplicative hashing using identity function: between 200K and 1 million collision, depending on the sequence.
Multiplicative hashing using randomisation function: around 450K collisions.
The best you can get with multiplicative hashing is by applying a randomisation hashing function prior to calculating hash table index. This shuffles the bits in random order, but this is still 450K more collisions than with a modulus functions. And has the additional expense of randomisation code – multiplication, bit rotations and xor operations. After all that, a single modulus instruction doesn’t look that bad.
Yes sometimes input data is quite random, sometimes you need to randomise it to avoid hash table attacks, etc. And sometimes you don’t need any of that – you already have a unique sequence of integers and modulus by a prime number will give you the least number of collisions. The fact that this gives sequential index values is a desirable property and what results in so few collisions. If you use something like linear probing then this is not a very smart way of resolving collisions, there are better ways. There is no optimal hash table design for all use cases, you need to take measurements and match to a specific hash table design. All I’m saying is that multiplicative hashing is no silver bullet and on many occasions involving sequential number sets, prime number modulus hashing is a much better choice.
And here is another test, I put the following functions into a separate shared library. So people can’t complain that compiler is optimising static constants.
#include <stdint.h>
uint64_t mul_index(uint64_t hash_code, uint64_t bits)
{
const uint64_t gr = UINT64_C(11400714819323198485);
}
uint64_t mod_index(uint64_t hash_code, uint64_t table_size)
{
return hash_code % table_size;
}
Measured time for a loop with 10,000,000 iterations for each function
Intel Xeon E5620 2.4GHz:
mul_index time = 91.76 msec
mod_index time = 157.84 msec
ARM Cortex-A72 1.5GHz:
mul_index time = 170.44 msec
mod_index time = 112.83 msec
The modulus function is slightly slower on Intel Xeon, but faster on ARM CPU. Feel free to run your own tests. On modern hardware, the speed of integer division is quite reasonable and not as horrible as some of you claim.
Typo: “desperate for a faster solution of this the problem”.
“this the”
Thanks. I tried fixing it, but at some point wordpress changed how its editor worked. Now whenever I edit old blog posts, all the formatting gets messed up. So I had to undo the change. Which still broke some formatting that worked before, but its the lesser evil. This blog post now has to be frozen as is…
With fast integer multiplication and division (even if the latter through shifting), one can just use a rational approximation of a Weyl sequence. Take (simple case), M=256, A=181, then compute the hash index as 181*X mod 256. If the input X doesn’t systematically have lots of powers of two, the result is very nicely distributed. The main point is to choose A and M so that A/M has only small partial quotients in its continued fraction expansion. This does not eliminate secondary clustering due to hash results being close. Fibonacci stuff works well with Fj-1/Fj always having 1s in its continued fraction expansion.
FWIW, ‘Introduction to Algorithms’ (2nd ed, Cormen et al., 1990) already gives a good exposition of what you call ‘Fibonacci Hashing’. However, there it’s called ‘The multiplication method’ (Section 11.3.2). That section cites Knuth for selection of a good multiplicand (i.e. (sqrt(5)-1)/2 * 2^w where w is the word size) and illustrates right-shifting the result by w-p bits (where the table size m = 2^p). That means the usage/relation of/to the golden-ratio isn’t mentioned, but the result is the same function as detailed in your article.
The point is that in that book the multiplication method section directly follows ‘The division method’ section and isn’t neglected at all. Since it follows the modulo prime hashing presentation in the division method section the reader is rather left with the impression that modulo prime isn’t the last word and using the multiplication method hashing is advantageous because of it’s simplicity. (the 4th edition also explicitly mentions that it’s fast).
It’s probably fair to say that this book is required reading in many computer science beginner courses all over the world since the 90ies (the 4th edition was published in 2022). Definitely it’s to a larger extend than ‘The Art of Programming’. Thus, your assessment that Ficonacci Hashing somehow was forgotten isn’t very convincing.
Great article, I also often use multiplicative hashing in my hash tables.
However, I think one important point is missing…
Back when I started programming in BASIC, I often did things like “INT(6 * RND()) + 1” to roll dice or “INT(32 * RND())” to pick from a deck of cards. RND() would return a real number in range [0..1), and it was kinda obvious that multiplying with the desired size M and rounding down would yield an integer in range [0..M-1].
That’s the gist of multiplicative hashing: you multiply with the table size rather than dividing by it, hence the name.
The problem with this is that it only works well for uniformly distributed data such as random numbers, while consecutive input values produce largely the same hash code. Therefore it is desirable to quasi-randomize the input data, e.g. using a simple linear congruential generator.
Now, if the table size M is a power of two, lets say 2^m, multiplying by the table size can be optimized to a shift-left m, which can be combined with the shift-right that strips the fractional bits, i.e. instead of “(rnd * M) >> 32” you do “rnd >> (32 – m)”. This is the version you presented in this article.
Unfortunately, the reason why its called multiplicative hashing and that it actually works for any table size (not just powers of two) is lost in this optimized form.
Btw. “fastrange” is Knuth’s multiplicative hash without the randomization step (or A := 1). So if you’ve combined your power-of-two fibonacci hash with fastrange, as mentioned in one of the comments, you probably ended up with the full version 😉
It seems to me that what’s happening here is you are misterming the two procedures which has caused quite a lot of struggle for me while reading the article. According to Wikipedia at least “A hash function is any function that can be used to map data of arbitrary size to fixed-size values”. While the step you call “Hash the key” seems to refer to cryptographic hash functions or as I understand it “encoding with a cipher” (assumption supported by you using strict avalanch criterion which seems to generally be applied for cryptographic hash functions), where the main purpose is to avoid getting original input out of the hash function knowledge.
With that “right” terminology used the Fibonacci hashing seems to be perfectly fine as a hashing function while we don’t get into cryptographic applications (or start dealing in a Fibonacci number multiples as you mentioned). At the same time the quote out of Knuth also starts to make sense, since it primarily refers to hashing and not cryptography.
So either you have used the wrong naming here or Wikipedia is using the wrong one (and then I understand nothing).
Otherwise thanks for the great and elaborate article, I’ve found it quite an interesting read and would be happy to use the knowledge when there’s a need.
Why not use the closest prime number to the magic constant? Would it not provide a better distribution?
Instead of 11400714819323198485 we could use one of the two closest prime numbers: 11400714819323198393 or 11400714819323198549
Maybe? I don’t understand why a prime number would help here. You clearly want an odd number to be coprime with powers of two, but I don’t see how being fully prime helps more.
[…] can do a fast modulus. There’s a description of the fast power of two modulus in this article on Fibonacci Hashing. The reason I’m not using a fibonacci hash is because I already am using a hash algorithm which […]