On Modern Hardware the Min-Max Heap beats a Binary Heap
by Malte Skarupke
The heap is a data structure that I use all the time and that others somehow use rarely. (I once had a coworker tell me that he knew some code was mine because it used a heap) Recently I was writing code that could really benefit from using a heap (as most code can) but I needed to be able to pop items from both ends. So I read up on double-ended priority queues and how to implement them. These are rare, but the most common implementation is the “Interval Heap” that can be explained quickly, has clean code and is only slightly slower than a binary heap. But there is an alternative called the “Min-Max Heap” that doesn’t have pretty code, but it has shorter dependency chains, which is important on modern hardware. As a result it often ends up faster than a binary heap, even though it allows you to pop from both ends. Which means there might be no reason to ever use a binary heap again.
Heap introduction
Before we go into the details, a quick refresher on the heap data structure. They’re classically used for priority queues, but they’re more generally useful whenever your objects have an ordering and you only care about a subset of the objects at a time. Say you only care about the top 10 items: A heap allows you to cheaply keep track of the top 10 items, even if the collection is often modified. Or maybe you have a scrolling view into a large list of items: No need to sort the whole collection. Only sort the currently visible selection and keep the rest as two heaps to cheaply update the view when new items are added, or when the user scrolls up or down. And finally a fun visual use is in this paper, where you have to quickly get the min out of a collection where all items are constantly changing. A heap is perfect for this, but you need a bit of extra storage to look up the position of items in the heap when you want to change them.
There are two alternatives to heaps:
- You could just sort the whole collection. But sorting is expensive, and a sorted collection is expensive to maintain if the collection often changes.
- You could use a tree data structure like a red-black tree or a B-tree or similar. These are a good choice if you need to search for items, but otherwise they are slower than heaps. (because they have to sort the collection in order to construct the tree)
What makes the heap special is that it has zero space overhead. You literally just store the items. To turn a collection into a heap you only change the order in which the items are stored. As long as the parent of an item is greater than or equal to its children, you have a heap. The parent of index i is at index (i-1)/2. The two children of index i are at (2*i)+1 and (2*i)+2.
To add an item to a heap you add it to the end and then check if it’s greater than its parent. If it is, then the heap property (parents have to be greater or equal to their children) was violated by the insertion and you have to swap the item up the chain of parents until everything is OK again.
To remove an item from the heap you swap it with the last item and pop it from the back. Now you have a swapped item in the wrong place, so you either have to trickle it up or down until the heap property is valid again. (meaning if its greater than its new parent, swap it up, if a child is greater than the new item, swap it with the larger child)
The largest item is always at index 0, and removing that item is a bit cheaper than removing random items, because you don’t have to check the case for trickling up.
You can also construct a min-heap by changing the order of all comparisons. In that case the smallest item will be at index 0.
The algorithms are all very simple and if you have implemented them once, you can always re-derive them by remembering that you just have to maintain the heap property (parents are greater or equal to their children).
Heap Performance
On modern hardware there are three big categories of things that hurt your performance:
- Cache problems: This can be a simple cache miss, or different threads fighting over cache lines. It’s a big category of performance problems
- Amdahl’s law: Whatever part of your code that doesn’t run in parallel will tend to dominate your runtime. This is true both at the large scale when it comes to using multiple threads, but also at the micro-scale when it comes to dependency chains ruining instruction-level parallelism
- Branch misprediction: This is much less of a problem than it used to be because branch predictors are amazing, but when it does hit you it can really hurt
There are obviously many more kinds of performance problems, like doing too much work or using the wrong algorithm, but these are the biggest hardware-related problems that will hurt you.
Heaps are very good for category 1: Since you have zero space overhead, and since a heap is usually just stored in a flat array, you will have few cache problems. When pushing a bunch of items, you’ll touch the same cache lines repeatedly so you’ll see good performance even on large heaps. But popping is less predictable and can jump around memory on large heaps, which can give you cache misses. But a heap will still do better than the alternatives.
Heaps are also good for category 3: Once again pushing is easy: (this will be a theme) If you’re using a heap for a priority queue, usually you’ll push at the back and pop at the front, so all comparisons of a push can be correctly predicted to false. But even when you’re not using a heap for a priority queue, and if you’re pushing completely unpredictable items, the branch predictor can do a good job: The first comparison has a 50/50 chance because it depends on if you’re in the upper half or lower half. But the next one can be predicted correctly 75% of the time because you only get to trickle up twice if you’re in the top 25% of items, and you only get to trickle up three times if you’re in the top 12.5% of items etc. So the branch predictor only gets better after that. But popping is harder again: You have to find the larger one of your children, and this will be completely unpredictable: the left child and right child are equally likely to move up. But you can make this branchless by calculating the child index as (2*i)+1+(child1<child2), and then this will be fast.
Where heaps have a problem is in category 2: Almost every single instruction depends on the previous instruction. The CPU can do very little instruction-level parallelism in heap push and pops. Once again pushing is slightly easier here because you can calculate the next index even before you know the result of the comparison, but popping is harder: You need to know whether the left or right child is bigger in order to know the next index, and you need to know the next index in order to start the next comparison. Nothing can happen in parallel.
So while heaps are generally very fast, we do now see where the performance of heaps could still be improved: We need to do something about those dependency chains. But first, I need to introduce the typical ways to implement double-ended priority queues:
Double-ended Heaps
There is a theme to heaps that adding something to a heap is easy, but getting data back out is harder. Push to the back is cheap, pop from the top is more expensive. Inserting a random item is easy, removing a random item either requires a linear search or extra bookkeeping to know where the item is. (with the extra bookkeeping the heap no longer has zero memory overhead, but it’s still very fast)
So double-ended heaps have a hard time: They want to make the more expensive operation, pop, more powerful. Not only should it be cheap to pop the top, but also to pop the bottom item from the heap.
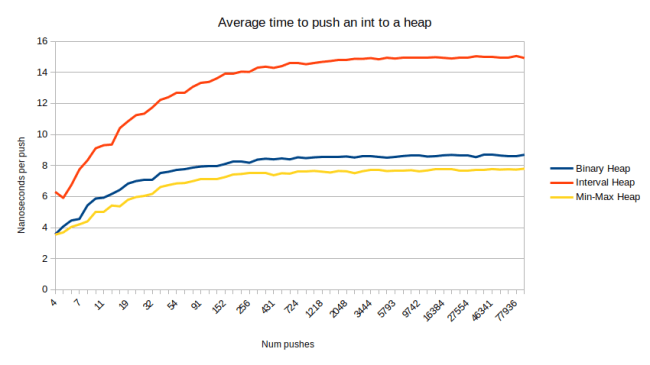
The Wikipedia article on the topic explains how to do this with an “Interval heap” which is a very elegant data structure: All the items at even indices form a min-heap, all the items at odd indices form a max-heap. So you can use normal heap operations, except that you have to enforce one extra property: The items in the min-heap have to be less than or equal to their matching item in the max-heap. If that’s enforced, then they define the interval that contains all the descendants of both items. (this is where the name comes from) It’s really elegant because we have a data structure that’s more powerful than a heap, but we still have zero space overhead: We just have a different arrangement of the same items. And it performs exactly as you’d expect: Pretty fast, but slightly slower than a binary heap because you have to do the normal heap operations, plus the comparison with the matching item in the other heap. Here is a graph where I pushed N items and divided the time by N to arrive at the time of an average push:
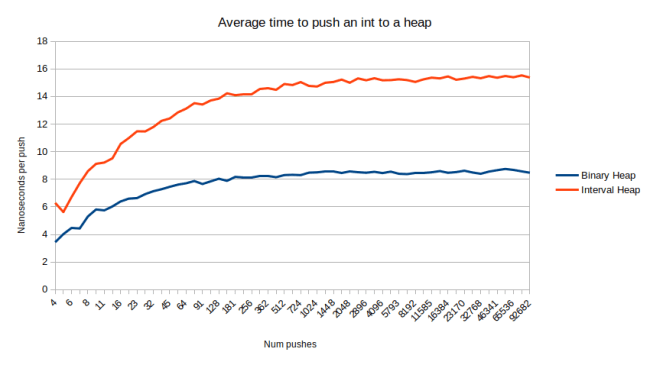
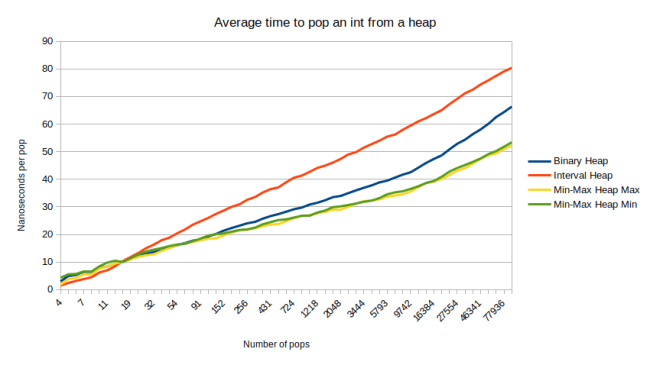
And here is the time to pop one int from the same heap:

So the interval heap isn’t slow, but it is slower than a binary heap. In case you’re wondering why the first graph flattens out but the second graph keeps increasing as the container gets bigger: Both of these operations have a worst-case performance of O(log n), so you’d expect them to grow with the size of the container (notice the log scale on the X axis), but I’m inserting random items here, and you only hit the worst case for push when inserting sorted items. When inserting random items, you have a 50% chance to trickle up once, a 25% chance to trickle up twice, 12.5% to trickle up three times etc. Meaning even though the heap gets bigger, the chance of doing more work goes down. So the graph flattens out.
But we didn’t come here for the interval heap. That’s just the data structure that everyone uses. What is this thing about the min-max heap that I keep on promising?
Min-Max Heap
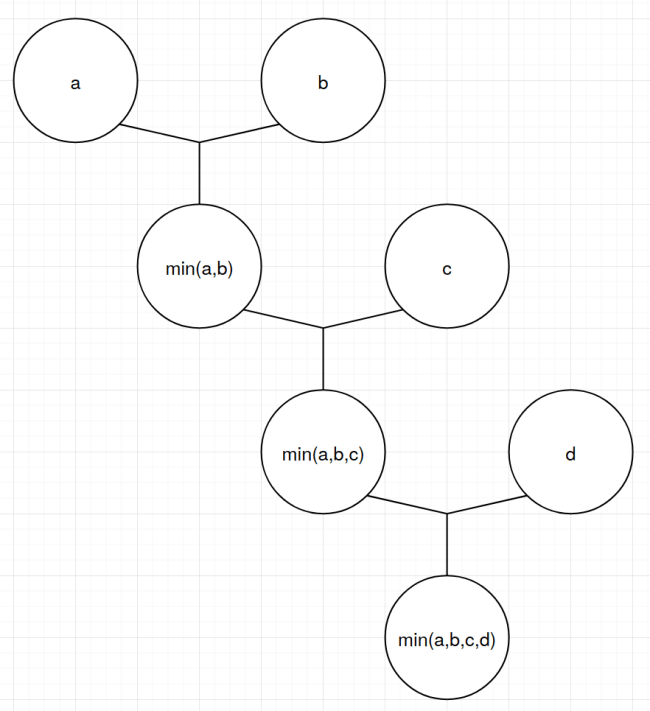
The min-max heap is a similar idea to the interval heap. Except that the min-max heap alternates on each layer. The first, third, fifth etc. layer are min-layers, the second, fourth, sixth etc. layer are max-layers. Items in the min-layers are smaller than all their descendants. Items in the max-layers are larger than all their descendants. Here is a picture from Wikipedia:

Looking at it like this, it’s not clear what the benefit is over the interval heap. And if you look at the pseudo-code in that Wikipedia article you’ll see things like “m := index of the smallest child or grandchild of i”. Meaning take the index i, check up to six descendants to see which one is the smallest, and assign the index of that to the variable m. No wonder nobody uses this.
But since I already primed you with the information about where the heap is slow, I want to draw your attention to one thing: We can often skip levels here. If I want to find the smallest descendant of the root, 8, in the picture above, I can skip the next level and only look at the grandchildren of 8. Meaning I only have to compare 31, 10, 11 and 16. Remember how the dependency chains were a performance problem of heaps? We still have the same problem, but now the chain is only half as long, because we only have to look at half as many layers. Sure, we have to do more work per layer, but we weren’t fully using the instruction-level parallelism of our CPUs anyway.
On a binary heap with N items, you end up with 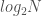
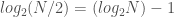

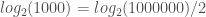
And here is the time to pop an item:
So in both cases the min-max heap is slightly faster than a binary heap. But remember that we’re not comparing two equivalent data structures here. There are two lines on the pop for the min-max heap: One for popping the min item, and one for popping the max item. Because the min-max heap is strictly more powerful than the binary heap. So it has more features and it’s faster. How often do you come across something like that?
(oh and yeah, I should also draw two lines for the Interval heap, one for popping min, and one for popping max, but I wanted to put the emphasis on the min-max heap)
One detail to point out is that popping max is slightly faster than popping min. At least for parts of the graph. I think the reason is that popping max has to look at fewer layers. This is just surprising because I initially expected the opposite: Popping max has to do more work initially, because there are two candidates for the max item, but this ends up being cheap if you make the initial comparison branchless, so the cost-saving of having one less layer to work with is more beneficial.
There is one final operation, make_heap(). This is a O(n) loop that can quickly turn any collection into a heap. It’s much faster than calling push_heap() over and over again. Here is how the min-max heap does for this operation:
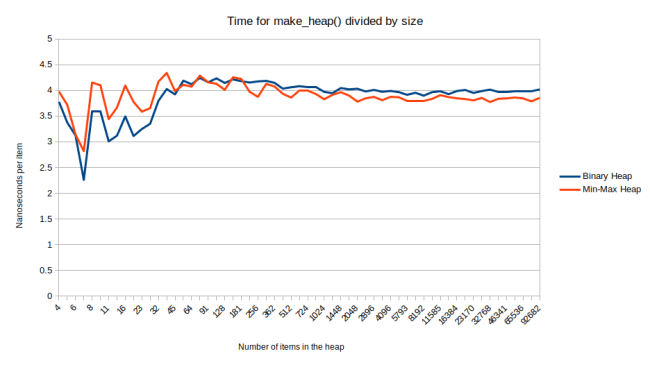
Here the min-max heap has pretty much the same speed as the binary heap, mainly because the binary heap is already really fast. (if you’re thinking that that binary heap looks awfully fast compared to your experience, you’ve just discovered that I’m not using the STL heap here. Libstdc++ has a really slow make_heap implementation, so for a fair comparison I had to write my own, faster make_heap. I’ll explain below) The y-axis jumps around early on but that’s not measurement noise: I chose a bit of a weird y-axis: the time to call make_heap divided by the number of items in the heap. This makes it easier to compare with the push_heap graph above, but it leads to initial jumpiness because the performance characteristics change a lot initially: In the graph above make_heap on 6 items takes 18 nanoseconds, on 7 items it takes 20 nanosecond, and on 8 items it takes 27 nanoseconds. So the time goes up, but I’m showing the average and the seventh item is cheaper than the average up to that point, so the average goes down. And then the eighth item is more expensive because it starts a new layer.
The min-max heap was invented in 1986, so how come nobody is using it? The answers are a bit hard to find because nobody is using it, leading to a lack of literature. It’s also really hard to google for the min-max heap, because Google just wants to show you articles about the normal binary Max heap, or the normal binary Min heap. Here is somebody who implemented a min-max heap in C++ and then said that after he was done he found an article that says that the interval heap is faster, so he kinda gave up on it. I think he must be referring to the paper “A Comparative Analysis of Three Different Priority Deques” by Skov & Olsen from 2001, which looks like a great paper (they even include source code) but it finds that the min-max heap to be really slow. Their problem is that they don’t do the trick of skipping layers when possible. But when a paper that clearly looks to be of a high quality (and I’m not being facetious here, I actually think it’s a very high quality paper) tells you that it’s slow, you believe it. I was just lucky that I didn’t see anything beyond the Wikipedia article, and that I had been thinking about what would be necessary to further speed up heaps. So lets talk about how to implement the min-max heap efficiently:
Implementing an Efficient Min-Max Heap
Lets start with pushing, because as always pushing is easier.
Push
When you push an item you first have to check if you’re on a min-layer or on a max-layer. If the heap (including the new item) is length 1, you’re on a min-layer. If the heap is length 2 or 3, you’re on a max layer. If the heap is length 4, 5, 6 or 7, you’re on a min-layer etc. The cheapest way of checking this is to use the position of the most significant bit. (at least I couldn’t find a cheaper way) Meaning use the “bit scan reverse” instruction and then check if the most significant bit as in an even- or odd-numbered position. It looks like C++20 finally added a way of accessing this instruction, using std::countl_zero. I don’t have C++20 though so I had to do it the old platform specific ways: Microsoft offers _BitScanReverse64(size), but on Linux you have to do (63 – __builtin_clzl(size)). The benefit of doing it like this is that I verified that my code actually just calls “bsr”, where the standard C++ version has an interface that might force it to do a branch. (Not sure about that though, so just check the assembly for extra branches if you’re able to use C++20)
The next thing you have to do in push is to check if you’re in the wrong layer: If the new item is in a min-layer, but it’s bigger than its parent in a max-layer, you have to swap the two. (or the other way round if the new item starts off in a max-layer) Then after that you can just normally trickle up by comparing to your grandparent, always skipping the layer between. My implementation is here. I used “goto” in the implementation because I couldn’t find a way to organize the initial switching without having to do additional comparisons. I’m sure there is a way to do it, but this doesn’t seem that bad since it’s just the initial switch.
Pop
Pop is harder, as usual. Popping the min-item starts off identical to popping on a binary heap. Popping the max-item requires us to find the largest of the first three items. If the heap is length 1, we’re done immediately because the only item is the largest item. If the heap is length 2, we’re also done immediately because the first item is in a min-layer, so the largest item is already at the end of the array. Otherwise the index of the largest item is 1+(heap[1]<heap[2]). Meaning we convert the result of the comparison to an integer and add it to 1, in order to not have a branch here. After we found the largest item, we swap it with the end of the array and then trickle down the item that used to be at the end and is now in the wrong position.
When trickling down we want to skip layers whenever possible. Luckily that’s possible on all but the last layer. When we reach a layer where we either don’t have two children, or we don’t have four grandchildren, that means we have reached the end of the iteration. So the check for the end of the iteration can be the same check that allows us to skip layers. That leaves us with two cases to handle: The common case when we have four grandchildren and can skip a layer, and the end-case when we can have any number of children or grandchildren.
In the common case we have to find the smallest item of our four grandchildren. (when popping the max-item just flip the logic in all my sentences from “smallest” to “largest.” There are no other differences) The four grandchildren are always right next to each other in the array, so this should be fast. To find the smallest of N items requires (N-1) comparisons, but it matters how we do them. If we compare them in-order (like std::min_element does) then we have a dependency chain from each comparison to the next and the CPU can only do one at a time. We can draw the dependency chain like this:
If we instead compare a to b and compare c to d, and then compare the result of both of those comparisons, we still have to do three comparisons, but the CPU can do the first two at the same time. We can draw the dependency chain like this:
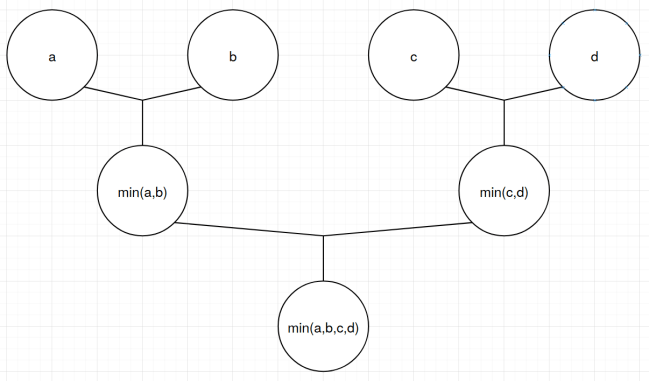
Even though both do three comparisons, we can expect this second one to run faster on modern hardware because it can use a little bit of instruction-level parallelism.
There is one other benefit to the second way of doing the comparisons. Since all four grandchildren are right next to each other, the first two comparisons can be branchless. The first one is (i + (heap[i + 1] < heap[i])), and the second one is (i + 2 + (heap[i + 3] < heap[i + 2])). Meaning we once again convert the results of the comparisons into integers.
And then my compiler even decided to turn the final comparison into a conditional move, so the whole thing is branchless. I think this branch is completely unpredictable, so it’s a good idea to use cmov here. Unfortunately I don’t think there is a way to force the compiler to do that, so I just got lucky. (if somebody knows how to force this, let me know in the comments)
Whenever you talk about branchless code it’s important to emphasize that branch predictors are amazing and often this branchless trickery will be slower than just doing a branch. In a sense this is actually a bad example. While it illustrates the point about dependency chains just fine, it has a problem with the branch predictor: the longer this chain is, the more you should prefer version 1. The reason is that the further you go down the chain, the better the branch predictor gets. On random items the last comparison in the first picture will be correctly predicted 75% of the time because there is only a 1/4 chance that the last item is the smallest. If the chain was longer, the percentages would go higher. On non-random items the branch predictor does even better. And a correctly predicted branch is almost free. So four items is just about the limit where this kind of trickery can be worth it. (or just measure which one is faster, which I did for this) But if the above diagrams wasn’t about branching but about multiplications or additions or something else instead, then version 2 should always beat version 1, so the point about dependency chains stands.
So that was the common case, when we have all four grandchildren and have to find the smallest item among them. What about the case at the end when we are either missing some grandchildren or are missing some children? I actually didn’t do anything fancy there. Just check how many of the descendants you have, and do different behavior depending on the number. You need to compare zero items, two items or three items. Never more than that, even though you have to find the min of up to five items. As an example imagine you have two children and two grandchildren:
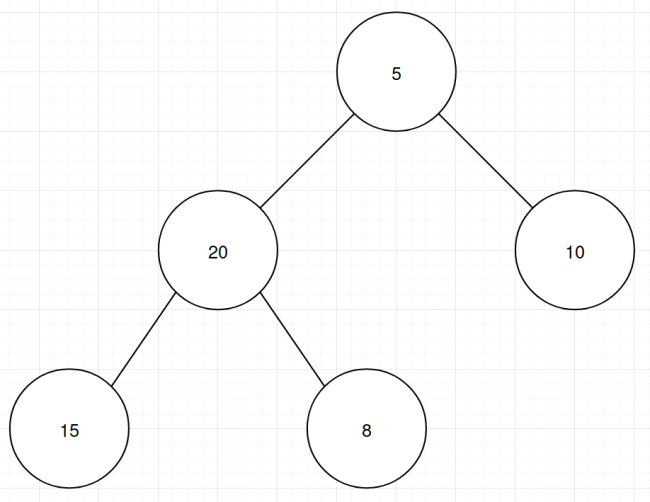
In this case you can ignore the first child because it has grandchildren. So you find the smaller of the two grandchildren and compare that to the second child. That’s two comparisons.
Make
I didn’t actually explain at the beginning how make_heap() works. Push and pop are all you need to understand heaps, but you need make_heap to quickly construct a heap. So let me first explain how it works for a binary heap before we move on to the min-max heap:
There are two potential ways of constructing a heap from random data: We could either iterate from the front and repeatedly use the push logic to trickle an item up into the right spot. Or we could iterate from the back and repeatedly use the pop logic to trickle an item down into the right spot.
Given that push is cheaper than pop, you’d think that you should iterate from the front, but that would result in an algorithm that’s O(n log n) in the worst case. (though it’ll be faster than that on average)
If we instead start from the end and trickle items down, we find that for the first few items there is nothing to do because they have no children. In fact half of all items have no children, so we can immediately skip over half the items. And another quarter have no grandchildren, which is also really fast. So only the remaining quarter of items actually need the looping trickle-down logic. This realization is why make_heap runs in O(n) time.
For a binary heap there is a proof here, but I’ll quickly give my intuition: Half the items have no work, and a quarter only require looking at one layer. One eighth require looking at two layers. One sixteenth need to look at three layers etc. This ends up as a sum of
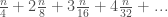
The denominator gets larger faster, so later terms approach 0. At this point I just plugged the first ten terms of this sum into a calculator and verified that the sum does approach 
For the min-max heap there is no fundamental difference here, except that we have to alternate between min and max layers. Luckily for us the switch happens at one less than the powers of two: 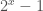
Besides this you just have to take advantage of the same trick as a binary heap: One quarter of items have no grandchildren, so you can use simpler logic for that. You could potentially also get an optimization out of the fact that one eighth of items have no great-grandchildren, but I haven’t tried that.
With that you now know how to efficiently implement a min-max heap, but I also have the code here. The relevant functions are push_minmax_heap, pop_minmax_heap_min, pop_minmax_heap_max, make_minmax_heap and is_minmax_heap. (equivalent to std::push_heap, std::pop_heap, std::make_heap and std::is_heap)
Now there is no reason to ever use a different kind of heap again. Or wait, is a binary heap really the best you can do? They’ve been around since the sixties, so haven’t people tried other optimizations? What is the fastest thing to do if you don’t need to be able to quickly find both ends of the heap? I’ve got all the answers for you, but I’m afraid you’ll have to come back for the next blog post. This one is long enough and has already exceeded my self-imposed time limit for how long I wanted to spend on this. So for now just know that the min-max heap is a great implementation of a double-ended priority queue, and should be preferred over the interval heap.
Appendix: Comparing to libstdc++
For all of the above benchmarks I didn’t use std::push_heap std::pop_heap or std::make_heap because they’re a bit slow in libstdc++. std::push_heap is mostly fine because, as always, pushing is easy, so lets talk about std::pop_heap.
When popping from a heap you remove the root leading to a gap in your data structure. The usual way to deal with that gap is to move the item from the end of the array into that slot and to then trickle it down until it’s in the right position. In a sense that’s bad though because the item at the end is probably small, so it’ll probably have to trickle all the way down again. So libstdc++ does something else: It finds the larger child and just unconditionally moves it up. Then it fills the new gap with its larger child again, repeating that procedure all the way down. When the gap is all the way at the bottom we still have to fill it because we can’t have gaps in the middle, so then libstdc++ moves the last item in the heap there. But now that item might be bigger than its parent, so it has to trickle up again.
I understand why libstdc++ does this, it really seems like it could be faster. But you’re doing strictly more work: You’re trickling all the way down and then up again. That’s more work than just trickling down. Sure, you have to do one less comparison while trickling down, but that comparison will usually be predicted correctly because the item that trickles down is always small. So you’re not saving much in exchange for the guarantee of having to do more work. I tried making their version fast because I really like it, but in the end it’s just slower for me. Here is std::pop_heap vs my binary pop_heap:

If I had just showed you this graph, the min-max heap would have been even more impressive. (this was the first graph I saw, it certainly got my hopes up…) But it wouldn’t have been entirely honest.
Up next is std::make_heap. I didn’t look into it too much because Andrei Alexandrescu already complained about the libstdc++ implementation of std::make_heap in this talk. So here is just the comparison of their make_heap to mine:
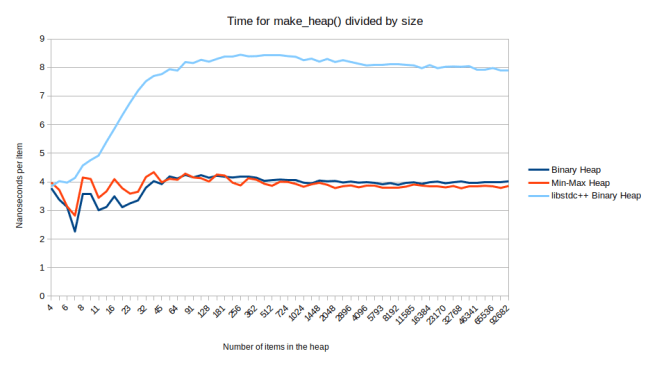
Once again I could have made the min-max heap look very impressive if I had compared it against libstdc++.
Looking briefly at the libstdc++ code, the problem seems to be that they’re just not doing much custom behavior for make_heap. They’re not taking advantage of the fact that 1/4 of all items have no grandchildren. And then they’re doing the same slow version of pop_heap as above where they trickle down and then trickle up again, which doesn’t make sense for make_heap.
The code for my binary heap is in the same file as for the min-max heap. It’s called “dary_heap” which is short for “d-ary heap” which is a generalization of the binary heap. So just set d=2. And if you want a sneak peek at the next blog post try setting d=4. Here is the code.

I believe 4-ary interval heap will be as fast as this min-max heap.
Interesting idea. I didn’t even think to investigate this. It seems like that would already be known if it was true since interval heaps are not super rare and quaternary heaps are not super rare, so surely someone must have thought of combining them before.
My first thought is that it’s probably not true because the min-max heap has to do less work per layer: When popping it just has to find the min of four items and compare that to the item that’s trickling down. The interval heap also has to compare against the matching item from the other heap.
That being said the difference is small enough that I think it’s worth trying. And they both would have to do approximately the same amount of work when pushing.
Thank you for very interesting post. I’m also very interested to see how the proposed min-max heap behaves compared to 4-ary heap (especially cache aligned). Can you please also post the code you have used for testing so others can save time while benchmarking the proposed implementation with existing codes?
I kinda gave it away in the last sentence: Yes, a quaternary heap will beat this min-max heap. You can already try it by using the d-ary heap from my code and setting D=4.
I decided to make a separate blog post about the quaternary heap, mainly because I needed more time to investigate potential optimizations for it.
About the benchmarks: That’s a totally reasonable request, unfortunately I have way too much custom code in my benchmarks to make it easy to share. I’ll port my benchmarks to use the Google Benchmark library. Then I can share them. I’ll either do that this evening or tomorrow evening.
I uploaded the benchmarks to the same repository here:
https://github.com/skarupke/heap
They’re not fancy, just calling the relevant instructions in a loop. The only difference is that I graph nanoseconds per item, where google benchmark gives you items per second.
Hey, would you be willing to share the source code you used to run the benchmarks? Interesting article, thanks!
Yes, I really should have shared my benchmarks… I’ll port my benchmarks to use the Google Benchmark library. That should make them easier to share. I’ll either do that this evening or tomorrow evening.
Same comment as above, I uploaded the benchmarks in the same repository here:
https://github.com/skarupke/heap
This is confused as written, but the idea’s right: branch prediction works better with heaps than trees.
Loosely, you expect the lowest level in a binary heap, where the item is initially placed, to be the bottom half of the item distribution, and that level’s direct parents are the third quarter of the item distribution. So the initial comparison is 5:3 against the newly inserted item trickling up.
This pattern is the same all the way up: given the comparisons that have gone before, the parent the item is being compared against is in the third quarter of the conditional item distribution, so the odds are again 5:3 against a trickle-up.
This isn’t that much, but it’s better than binary trees, which are exactly even odds each time (and never mind rebalancing operations), and it’s enough to give the branch predictor something to work with.
I wonder if dependency chains are the primary reason for speedup here? Another potential benefit is that the four elements we are looking at are consecutive in memory, potentially in the same cache line.
That is, I wouldn’t be surprised to see a speedup here even without parallel comparison (doing
min(1, min(2, min(3, 4)))rather thanmin(min(1, 2), min(3, 4))). But I also won’t be surprised by not seeing it — I don’t have an intuition about how the two factors compare to each other.I have to admit that it’s a bit hard to figure out what exactly led to the speed-up. In my code
min(min(1, 2), min(3, 4)) ended up branchless, and min(1, min(2, min(3, 4))) did not end up branchless. So it could either be the shorter dependency chain, or the branchless code that could have led to the speed-up. Or both. But in a binary heap all siblings are also always right next to each other in memory.
I did measure that for an octonary heap the chaining version is faster. Meaning min(1, min(2, min(3, min(4, min(5, min(6, min(7, 8))))))) is faster than min(min(min(1, 2), min(3, 4)), min(min(5, 6), min(7, 8)))). And I’m pretty sure the reason is what I said in the blog post: The longer the chain, the better the branch predictor gets. min(1, 2) is mostly unpredictable, but the last min in that long chain is very predictable because on random items the chance that the last is the smallest is only 1/8.
Could I avoid the bit scan reverse in less-capable bitwise languages? I am thinking in particular of something like converting (x & 0xAA…A) < (x & 0x55…5) to an int, but you mention something about an interface which might cause a branch misprediction and so I imagine it depends on the code that follows it whether this is sufficient…
I think your trick might work. That’s pretty clever. My first solution would have involved much more work if I hadn’t been able to use bit scan reverse…
The talk about the interface of branch misprediction is about how C++20 decided to standardize the access to the “bit scan reverse” instruction. I don’t know if their way of standardizing isn’t adding unnecessary overhead. So if you have the option between using “bit scan reverse” directly and using the C++20 library function, you should probably try the C++20 library function first, but check that it isn’t doing more work than if you used “bit scan reverse” directly. The reason for their overhead is that “bit scan reverse” returns nonsense when it’s called on 0. So the C++20 standard decided to define behavior for that edge case. But I never call “bit scan reverse” on 0, so I don’t need logic for handling that edge case.
I wrapped your code and also did some benchmarking which can be found here https://github.com/Janos95/Heap . Maybe I screwed something up when wrapping your code, but in my measurement the stl heap is acutally among the best performing.
Best Whiches
Janos
I wrapped your code and also did some benchmarking which can be found here https://github.com/Janos95/Heap . Maybe I screwed something up when wrapping your code, but in my measurement the stl heap is actually among the best performing.
Best Whiches
ok I added some more benchmarks which indeed show similar numbers than what you have :). Only the first benchmark of extracting and the pushing into the heap are a bit odd (in particular in seems to hit some performance bug in your binary heap implementation)
Interesting. I’ll try to investigate where the performance difference comes from.
There is a problem with that benchmark in that repeatedly popping the top item and pushing a random item leads to a degenerate case where the new item will almost always be the top item. The reason is that the first few pops remove all large items, and then a random insert will usually be larger than the largest remaining items in the heap. (if it isn’t, then the average just goes further down and future items are even more likely to be the top item)
So it could be that in this case all the branches are very predictable and all my branchless trickery ends up backfiring.
What libstdc++ actually makes sense for more complex objects (opposite to int that you are using for benchmarks), because they use move construction instead of a swap as their basis operation (and swap is equivalent to three moves in a general case) .
Great article!
Are you familiar with Min-Max Fine Heaps?
https://arxiv.org/abs/cs/0007043
Hmm. I think the major speedup is simply from CPU speculatively loading multiple branches of the heap ahead of time. Using quaternary heap instead would most likely make it even faster for big heaps.
Nice investigation and the blog post tho. min-max heaps are not well known, and they deserve more exposition like that!
Awesome post! I’ve still to look at the code, however a hybrid D-ary – Min/Max heap might be nice. Today I am optimizing the Priority Queue for my A*. I will need min / max PQ functionality later. Thanks!
Hmmm… once more I am reminded of all the coolness I relinquished when I chose C# on Unity instead of C++ on Unreal. However, your C++ code was a lifeline while I thrashed out a C# metaphor of this elegant min/max heap algorithm! Thanks again!
Hi, really nice article, thank you for sharing it with us.
I tried to implement min-max heap in C# and did this optimizations…
1) If you store first element not on index 0 but on index 1, then you can simplify computations of indeces a little bit:
– left-child-index = parent-index2 (instead of parent-index2+1)
– parent-index = child-index/2 (instead of (child-index-1)/2)
and so on… and I’m using left/right shifting instead of multiplication/division. But you probably know all this :).
2) Instead of “insert & swaps” (in bubble-up & bubble-down operations) I did “moves & insert”. It can save almost half of assignments.
BR,
Martin
Hi,
you have done good work, but I have one question about the functionality of min-max heap, I tried to use your code, and I can’t sequentially do pop_min and pop_max operations, it seems that I can only do one of them, otherwise the data will be corrupted.
I want to know it was designed to do like that, or it is mistake.
Thanks, Rafayel.
That’s definitely unexpected. You should be able to call both pop_min and pop_max operations. Can you post an example that shows the problem?
Sorry for my confusing question
I want to say, that for example in this vector {2, 5, 7, 4, 9, 6}
if I will to only pop_min (pop_max) operation 6 times the vector will be sorted, but if we will switch to min-max heap’s interface it allows both operations pop_min and pop_max and one of the reasons of using min-max heap is to do these operations sequentially to each other.
If I will do pop_min and pop_max operations each in 3 times I wouldn’t get the sorted vector.
I know that this is because both operations are working with the end of the vector and expect sorted order will be non-realistic. However, did you notice that one of the heap’s properties is lost? The result in the standard heap will be sorted.
Not sure if I got the example right, but this seems to be giving the expected output when I run it.
1. Call make_minmax_heap
2. Call pop_minmax_heap_min three times, which pops 2, 4 and 5, as expected
3. Call pop_minmax_heap_max three times, which pops 9, 7, and 6, as expected
See the code below. This prints “2 4 5 9 7 6” for me:
Can you post code that shows the problem?
Yes, you are right, this is expected output, but from the view of sorted order Min-Max Heap loses the property of standard priority queues. I want to modify the Min-Max Heap for heap sort.
I see. Min-max heaps maintain a slightly different heap property, so they won’t work with the normal heap functions.
You can still use them for heap sort if you only call the min-max heap functions. Meaning call make_minmax_heap followed by pop_minmax_heap_min in a loop.
Did you tried to use Deap data structure, I tried from this git repo https://github.com/Gamma234/Heap and for pop_min got 2x faster results, but not fully tested just measuring time for pop all elements from two data structures.
Thanks, Rafayel.
I haven’t heard of the Deap before. It certainly looks interesting. Are you saying it’s 2x faster than the min max heap? At first glance I don’t see a reason why that should be, but I would be very happy if this was true, especially for the pop_min function.(it would make for a very fast heap sort)
I just tested with counting duration with chrono, for 100 elements the difference is about by 1.5x, and for 1000000 elements the difference is by 1.7x.
I tried benchmarking it and I just don’t see it. The deap is always slower than the min_max heap, which is what I would have expected. Can you post your benchmark somewhere?
At 100 elements
The Deap takes ~23ns to pop min, on average
The min_max_heap takes ~21ns to pop min, on average
At 100,000 elements
The Deap takes ~70ns to pop min, on average
The min_max_heap takes ~49ns to pop min, on average
Note that this is a slightly unfair comparison: In the deap it’s cheaper to pop min, in the min_max_heap it’s cheaper to pop max. So a fair comparison would compare popping min from the deap to popping max from the min_max_heap. (and then you can flip the comparison function to make the behavior identical)
I tested deap like this
auto start = std::chrono::high_resolution_clock::now(); int data; for ( int i = 0 ; i < num_items / 2 ; i++ ) { mmHeap->GetMinAndDelete(data); } auto end = std::chrono::high_resolution_clock::now(); auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start);and for 100,000 elements I got in average 12,547 microseconds.
And for Min-Max Heap
auto start = std::chrono::high_resolution_clock::now(); while (size > 0) { pop_minmax_heap_min(heap.begin(), heap.begin() + size); --size; } auto end = std::chrono::high_resolution_clock::now(); auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start); std::cout << "Time taken by function: " << duration.count() << " microseconds\n";for Min-Max Heap 44,829 microseconds in average
I copy+pasted your code to godbolt and got opposite results:
https://godbolt.org/z/En5G3crM8
Deap: 8822us
Min-max heap: 3346us
Are you running with optimizations? Your numbers seem too big.
Hello, sorry for answering too late, yes, I runed my tests whiteout optimizations.
Hello! Great post, thanks!
What do you think about the performance in the case of a heavy comparison functor?
Like long strings or something in between — virtual call to compare integers?
A while ago I used a tournament tree (which is basically implemented as a segment tree) to speed up the merging of k “iterators”: https://github.com/iresearch-toolkit/iresearch/pull/530
I noticed that this is always faster than std-heap, because we used a pessimistic approach for the heap (pop then push).
I think there are at least two places in databases where heap-like data structure performance is really important.
Merge k sorted sequences, almost every database that uses lsm tree has something like this. As an example, rocksdb used the optimistic heap approach https://github.com/facebook/rocksdb/blob/main/util/heap.h#L17
This place is especially interesting because they can use two heaps, min and max, https://github.com/facebook/rocksdb/blob/main/table/merging_iterator.cc#L19
Get the top k elements from an unordered sequence, by the way, this can be done without a heap https://github.com/quickwit-oss/tantivy/commit/b525f653c09726c9f97d35ee15aea1d557bce4f2
So if you’re interested in popularizing min and max heap, you might want to try speeding up some real open source code 🙂