Beautiful Branchless Binary Search
by Malte Skarupke
I read a blog post by Alex Muscar, “Beautiful Binary Search in D“. It describes a binary search called “Shar’s algorithm”. I’d never heard of it and it’s impossible to google, but looking at the algorithm I couldn’t help but think “this is branchless.” And who knew that there could be a branchless binary search? So I did the work to translate it into a algorithm for C++ iterators, no longer requiring one-based indexing or fixed-size arrays.
In GCC it is more than twice as fast as std::lower_bound, which is already a very high quality binary search. The search loop is simple and the generated assembly is beautiful. I’m astonished that this exists and nobody seems to be using it…
Lets start with the code:
template<typename It, typename T, typename Cmp>
It branchless_lower_bound(It begin, It end, const T & value, Cmp && compare)
{
size_t length = end - begin;
if (length == 0)
return end;
size_t step = bit_floor(length);
if (step != length && compare(begin[step], value))
{
length -= step + 1;
if (length == 0)
return end;
step = bit_ceil(length);
begin = end - step;
}
for (step /= 2; step != 0; step /= 2)
{
if (compare(begin[step], value))
begin += step;
}
return begin + compare(*begin, value);
}
template<typename It, typename T>
It branchless_lower_bound(It begin, It end, const T & value)
{
return branchless_lower_bound(begin, end, value, std::less<>{});
}
I said the search loop is simple, but unfortunately the setup in lines 4 to 15 is not. Lets skip it for now. Most of the work happens in the loop in lines 16 to 20.
Branchless
The loop may not look branchless because I clearly have a loop conditional and an if-statement in the loop body. Let me defend both of these:
- The if-statement will be compiled to a CMOV (conditional move) instruction, meaning there is no branch. At least GCC does this. I could not get Clang to make this one branchless, no matter how clever I tried to be. So I decided to not be clever, since that works for GCC. I wish C++ just allowed me to use CMOV directly…
- The loop condition is a branch, but it only depends on the length of the array. So it can be predicted very well and we don’t have to worry about it. The linked blog post fully unrolls the loop, which makes this branch go away, but in my benchmarks unrolling was actually slower because the function body became too big to be inlined. So I kept it as is.
Algorithm
So now that I’ve explained that the title refers to the fact that one branch is gone and the other is nearly free and could be removed if we wanted to, how does this actually work?
The important variable is the “step” variable, line 7. We’re going to jump in powers of two. If the array is 64 elements long, it will have the values 64, 32, 16, 8, 4, 2, 1. It gets initialized to the nearest smaller power-of-two of the input length. So if the input is 22 elements long, this will be 16. My compiler doesn’t have the new std::bit_floor function, so I wrote my own to round down to the nearest power of two. This should just be replaced with a call to std::bit_floor once C++20 is more widely supported.
We’re always going to do steps that are power-of-two sized, but that’s going to be a problem if the input length is not a power of two. So in lines 8 to 15 we check if the middle is less than the search value. If it is, we’re going to search the last elements. Or to make it concrete: If the input is length 22, and that boolean is false, we’ll search the first 16 elements, from index 0 to 15. If that conditional is true, we’ll search the last 8 elements, from index 14 to 21.
input 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
line 8 compare 16
when false 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
when true 14 15 16 17 18 19 20 21Yes, that means that indices 14, 15 and 16 get included in the second half even though we already ruled them out with the comparison in line 8, but that’s the price we pay for having a nice loop. We have to round up to a power of two.
Performance
How does it perform? It’s incredibly fast in GCC:
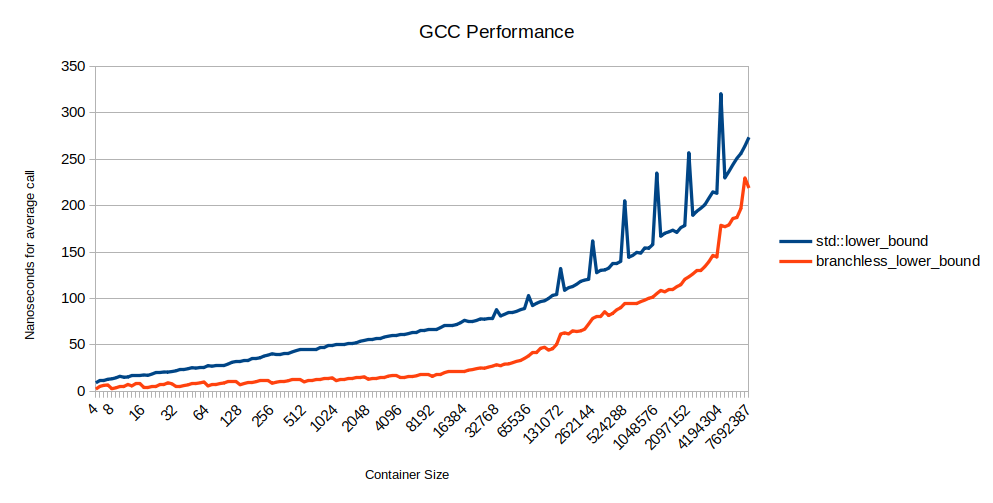
Somewhere around 16k elements in the array, it’s actually 3x as fast as std::lower_bound. Later, cache effects start to dominate so the reduced branch misses matter less.
Those spikes for std::lower_bound are on powers of two, where it is somehow much slower. I looked into it a little bit but can’t come up with an easy explanation. The Clang version has the same spikes even though it compiles to very different assembly.
In fact in Clang branchless_lower_bound is slower than std::lower_bound because I couldn’t get it to actually be branchless:
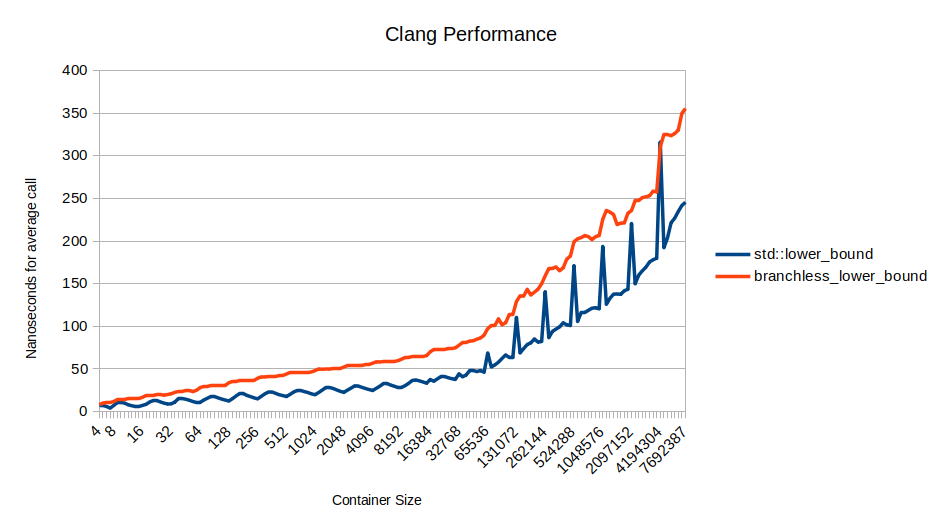
The funny thing is that Clang compiles std::lower_bound to be branchless. So std::lower_bound is faster in Clang than in GCC, and my branchless_lower_bound is not branchless. Not only did the red line move up, the blue line also moved down.
But that means if we compare the Clang version of std::lower_bound against the GCC version of branchless_lower_bound, we can compare two branchless algorithms. Lets do that:

The branchless version of branchless_lower_bound is faster than the branchless version of std::lower_bound. On the left half of the graph, where the arrays are smaller, it’s 1.5x as fast on average. Why? Mainly because the inner loop is so tight. Here is the assembly for the two:
| inner loop of std::lower_bound | inner loop of branchless_lower_bound |
|---|---|
| loop: mov %rcx,%rsi | loop: lea (%rdx,%rax,4),%rcx |
| mov %rbx,%rdx | cmp (%rcx),%esi |
| shr %rdx | cmovg %rcx,%rdx |
| mov %rdx,%rdi | shr %rax |
| not %rdi | jne loop |
| add %rbx,%rdi | |
| cmp %eax,(%rcx,%rdx,4) | |
| lea 0x4(%rcx,%rdx,4),%rcx | |
| cmovge %rsi,%rcx | |
| cmovge %rdx,%rdi | |
| mov %rdi,%rbx | |
| test %rdi,%rdi | |
| jg loop |
These are all pretty cheap operations with only a little bit of instruction-level-parallelism, (each loop iteration depends on the previous, so instructions-per-clock are low for both of these) so we can estimate their cost just by counting them. 13 vs 5 is a big decrease. Specifically two differences matter:
- branchless_lower_bound only has to keep track of one pointer instead of two pointers
- std::lower_bound has to recompute the size after each iteration. In branchless_lower_bound the size of the next iteration does not depend on the previous iteration
So this is great, except that the comparison function is provided by the user and, if it is much bigger, it can take many more cycles than we do. In that case branchless_lower_bound will be slower than std::lower_bound. Here is binary searching of strings, which gets more expensive once the container gets large:

More Comparisons
Why is it slower for strings? Because this does more comparisons than std::lower_bound. Splitting into powers of two is actually not ideal. For example if the input is the array [0, 1, 2, 3, 4] and we’re looking for the middle, element 2, this behaves pretty badly:
| std::lower_bound | branchless_lower_bound |
|---|---|
| compare at index 2, not less | compare at index 4, not less |
| compare at index 1, less | compare at index 2, not less |
| done, found at index 2 | compare at index 1, less |
| compare at index 1, less | |
| done, found at index 2 |
So we’re doing four comparisons here where std::lower_bound only needs two. I picked an example where it’s particularly clumsy, starting far from the middle and comparing the same index twice. It seems like you should be able to clean this up, but when I tried I always ended up making it slower.
But it won’t be too much worse than an ideal binary search. For an array that’s less than 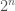
– an ideal binary search will use 
– branchless_lower_bound will use 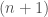
Overall it’s worth it: We’re doing more iterations, but we’re doing those extra iterations so much more quickly that it comes out significantly faster in the end. You just need to keep in mind that if your comparison function is expensive, std::lower_bound might be a better choice.
Tracking Down the Source
I said at the beginning that “Shar’s algorithm” is impossible to google. Alex Muscar said he read it in a book written in 1982 by John L Bentley. Luckily that book is available to borrow online from the Internet Archive. Bentley provides the source code and says that it’s got the idea from Knuth’s “Sorting and Searching”. Knuth did not provide source code. He only sketched out the idea in his book, and says that it came from Leonard E Shar in 1971. I don’t know where Shar wrote up the idea. Maybe he just told it to Knuth.
This is the second time that I came across an algorithm in Knuth’s books that is brilliant and should be used more widely but somehow was forgotten. Maybe I should actually read the book… It’s just really hard to see which ideas are good and which ones aren’t. For example immediately after sketching out Shar’s algorithm, Knuth spends far more time going over a binary search based on the Fibonacci sequence. It’s faster if you can’t quickly divide integers by 2, and instead only have addition and subtraction. So it’s probably useless, but who knows? When reading Knuth’s book, you have to assume that most algorithms are useless, and that the good things have been highlighted by someone already. Luckily for people like me, there seem to still be a few hidden gems.
Code
The code for this is available here. It’s released under the boost license.
Also I’m trying out a donation button. If open source work like this is valuable for you, consider paying for it. The recommended donation is $20 (or your local cost for an item on a restaurant menu) for individuals, or $1000 for organizations. (or your local cost of hiring a contractor for a day) But any amount is appreciated:
Make a one-time donation
Choose an amount
Or enter a custom amount
Thanks! I have no idea how much this is worth to people. Feedback appreciated.

To generate branchless code in Clang, one can use
__builtin_expect_with_probabilityor__builtin_unpredictable. They are not guaranteed though.By the way, there is a bit more discussion on efficient binary search that you might have interest in: https://en.algorithmica.org/hpc/data-structures/binary-search/
Thanks, I had tried __builtin_unpredictable but it didn’t work for me.
That blog post is very interesting. He came up with a very similar loop to Shar’s algorithm by starting from lower_bound and doing some reasonable simplifications. I’ll try to add it to my benchmarks this evening.
And here is a link to godbolt showing that __builtin_unpredictable doesn’t help:
https://godbolt.org/z/zG53jTh65
I ran the benchmarks on the branchless binary search from the algorithmica link:
The graph is slightly more noisy because I didn’t run the benchmark enough times for the averages to smooth out.
It’s definitely fast, slightly faster than the Clang branchless version of std::lower_bound. (not shown here) But it’s slightly slower than branchless_lower_bound. (except on the right side of the graph, where it’s the same speed)
Curiously the prefetching just makes it slower for me. Might be something about my benchmark setup because I’m searching in the same array multiple times…
On microbenchmarks, the “Shar” optimization may have an effect, but I am not sure it would be on production code, where most of the time is likely to be spent putting the data into L1 cache, not searching within the data. This may be one of the reasons why it was not so widely used – because it is not worth it on real work.
I think the right side of my graphs should capture that case, when data isn’t in cache. There is still a meaningful speedup.
I think the most likely explanation is that this one does more comparisons. And if the compiler doesn’t make it branchless, it is slower after all. Plus we only had the one-based-indexing version before and converting it to zero-based indexing was surprisingly tricky. Try it yourself without looking at my code.
This was a couple weeks of work, which most people wouldn’t try for an algorithm that does more comparisons.
A similar trick can be done for the Eytzinger layout: https://espindo.la/posts/array-layouts.html
Thanks. I really like the idea of the Eytzinger layout, but I don’t know if the Eytzinger layout is useful for anything other than fast binary search. A sorted array is useful for other things (like to display things in sorted order), so you might already have sorted data and then you want to use binary search. And if you don’t need it to be sorted, using a good hash table is going to be faster.
So I have never yet come up with a reason to actually use the Eytzinger layout. Am I missing something?
For large arrays it is better as you can prefetch. The paper that got me started on this is https://arxiv.org/abs/1509.05053, but yes, for the array sizes I was interested in binary search was better.
It is usually easier to get clang to produce cmov than gcc.
Try a conditional expression:
Thanks, but it doesn’t seem to help:
https://godbolt.org/z/KE634cf7K
I believe cmovxx are by default converted to branches by LLVM, based on the principle that they are said to be slow. In case you would not have tried (you are not very clear on what’s been tried or not), then add the flag combination
to keep them, at least here https://godbolt.org/z/aTExEYcfY, I can see one that appear
Thanks, that worked. With this, Clang also compiles branchless_lower_bound to be faster than std::lower_bound.
I think the argument for not allowing cmov goes something like this:
1. Well-predicted branches are faster than cmov
2. Most branches can be well-predicted
3. Therefore most uses of cmov are actually slower
This is all true, and I’m sure you could construct a benchmark of binary search where a branch is faster than cmov, but some branches are actually just hard to predict.
I wish I could just control this. 99% of the time I wouldn’t use that feature, but occasionally I do want to actually remove a branch.
Strange, when I try it in Godbolt in isolation, Clang 16 generates a “cmove” instruction, G++ 13 a “cmovne”. (“-std=c++20 -O2 -mavx2”).
Changing to
begin += -compare(…) & step;
Clang generates the same code, where G++ generates the “and” instruction, which should do OK. Gcc has generated consistently faster production code than Clang’s, whenever I have tried it.
I explore this sort of thing in more detail in http://cantrip.org/sortfast.html . There is also https://www.youtube.com/watch?v=1RIPMQQRBWk&pp=ygUTY3BwY29uIG9wdGltaXphdGlvbg%3D%3D and https://www.youtube.com/watch?v=g-WPhYREFjk&pp=ygUTY3BwY29uIG9wdGltaXphdGlvbg%3D%3D
In your Godbolt code, g++ 16 generates a “cmovg” either way, and I have found no way short of the “-x86-cmov-converter=false” trick to dissuade it, despite that CPUs are enormously better than before at avoiding cmov performance hits.
See https://en.algorithmica.org/hpc/cpu-cache/associativity/ re: the poor power-of-two-array-size performance.
Thanks, that’s a fascinating link. But wouldn’t that suggest that branchless_binary_search should be slower than std::lower_bound? Because branchless_binary_search always operates on powers of two, but std::lower_bound will be off-by-one every time that it steps into the right half.
Good point, the mental model I built after reading that cache-associativity article still doesn’t seem sufficient to explain your benchmark result. It may be necessary to look at and tweak the exact benchmark code to figure out why std::lower_bound appears to be more rather than less affected, and estimate whether/when it’s worthwhile to explicitly try to avoid multiple-of-4KiB step sizes.
Off-by-one doesn’t negate cache associativity. Data is loaded in cache line (64B for most architecture). Getting a data that is “one-off” would still be in the same cache line as another data that isn’t one-off.
My guess as to why the “spike” is more prominant on lower_bound:
– First, we see the “spike” when containers are of power of twos, which usually imply that the bottleneck is memory-bounded.
– For std::lower_bound, we could either go “left” or “right”. It’s very hard for the branch predictor to properly determine which way to go, so it cannot effective prefetch the next data.
– For your implementation of branchless_lower_bound, you access data in “halves”, so it is easier to predict and thus, prefetch data, hence the spike (memory-bound) isn’t too high.
But again, I’m just guessing.
Didn’t find the reference in “Writing Efficient Programs”, Bentley’s 1982 book. He does refer to Knuth but I don’t see any algorithm but what you call “standard”. (https://archive.org/details/writingefficient00bent)
The algorithm is on page 128:
https://archive.org/details/writingefficient00bent/page/128/mode/2up?view=theater
This exactly matches the code in the blog post that I link to at the top.
He says that it came from Knuth on the previous page. To find it in Knuth’s book look in the index for “Shar”.
OK sorry I’m dumb. I looked at that page and thought oh, unrolled loop big deal, not seeing the binary constants. Your version rolled the loop up again 😉 and generalized it to tables of size other than 1000.
I really enjoyed this article. So much so that I decided to implement the same algorithm in my favorite language (Python). It beats the best pure-Python bisect_left implementation I could find, and also beats the standard library bisect_left implementation (albeit implemented using C-extensions this time, but the same idea). https://github.com/juliusgeo/branchless_bisect
I’m giving this a try but I’m a bit confused for 2 reasons 🙂
1) You made your own std::bit_floor function since std::bit_floor is only in C++20, but you use std::countl_zero which is a C++20 function.
2) Isn’t gcc a C compiler? g++ is the equivalent GNU c++ compiler.
I changed the code as you suggested to use std::bit_floor since I had to compile with C++20 anyhow for the std::countl_zero calls. Any insight you could shed would be helpful! I’m compiling this on an M1 Mac running Ventura since that might explain the difference. Thanks!
Yes, both bit_floor and countl_zero are C++20. But I think supporting countl_zero is easier because it just wraps an intrinsic. Maybe that’s why one was supported and not the other. I’m sure if I upgrade compilers, both would work.
Yes, on the command line I call g++. Maybe I’m wrong on this, but I’ve often heard the C++ compiler also called GCC. So when comparing clang and gcc, I’ve never heard anyone say “clang and g++” instead.
Great article! From one blogger who uses math notation to another: if you want wordpress to render LaTeX better, and avoid the weird default latex fences, try installing the Simple MathJaX plugin https://wordpress.org/plugins/simple-mathjax/
Check out this implementation which is about 10% faster than the one in this article 🙂
https://gitflic.ru/project/erthink/bsearch-try
Thanks, I really like this one. I compared it and it does come out faster in my benchmarks as well, particularly when the array is large:
For me the mini0 is actually fastest for small arrays, which is mostly where I’d use it. mini2 is fastest in large arrays. I only plotted those two because others weren’t performing that well.
The function is nice and tight. It’s a good compromise to round the size up and divide in half. That makes it only depend on itself, and it allows calculating the size one iteration ahead of time. Just neat.
I’m tempted to give it an interface that matches std::lower_bound.
It seems to me that the number of comparisons can be slightly improved.
When the length is odd, the middle element cleanly divides the array into two length / 2 (rounded down) pieces. However, when it is even, the latter half is shorter.
The next length is computed as (length + 1) / 2 – stepped. This works correctly in the even case but in the odd when no step was taken the new length is off by one. A better formula is (length – stepped) / 2.
I’d assume that formula produces just as good assembly, so it should result in a slight performance increase overall.
Great stuff!
My two cents:
https://github.com/aliakseis/lower_bound_ex
Shar’s algorithm a.k.a. Knuth’s Algorithm U has a cleaner C/C++ implementation in https://arxiv.org/pdf/1509.05053.pdf section 3.1.3. In particular, compiling Listing 2 in clang for macOS M1 does yield inner-loop branch free code.
(You might want to change the conditional assign to an if, clang should still be smart enough to substitute a condition move opcode. Also if you keep a const pointer and just update an index, you may get a smidgen better perf as well.)
That looks closer to the branchless binary search from the algorithmica article that the first comment posted about. It’s a very similar loop, except that it updates three variables (size, step and index) instead of two variables for Shar’s algorithm. (step and index)
I just added a response to the first comment where I benchmark this. It comes out very fast, but slightly slower than Shar’s algorithm.
For using an index instead of modifying the “begin” variable: I had tried that and it just came out slower. I think the problem is that we’re not ever reading from the current index, but always from index + step. So instead of
compare(begin[step], value)
we have to write
compare(begin[index + step], value)
Meaning we have to always add three things instead of two.
Assuming you are talking about my https://gitflic.ru/project/erthink/bsearch-try
So you were missing some things.
Shar’s algorithm has fewer operations inside the loop, but on most microarchitectures, some operations inside loop of my implementation can (and will) be performed in parallel.
On average Shar’s algorithm requires one more iteration of the cycle, since it starts not from the middle, but at a power of 2.
Shar’s algorithm has slightly more overhead, since requires preparatory actions, including two conditional branches one of which is poorly predicted.
All of this allows my implementation to work a little faster, which is confirmed by benchmarks. For instance on i7-1280P with gcc 12.2:
Function
Time
Diff
Ratio
ly_bl_mini2
0.135552
-77.21%
4.39
ly_bl_mini3
0.138640
-76.69%
4.29
ly_bl_mini1
0.140435
-76.39%
4.23
ly_bl_mini0
0.141575
-76.19%
4.20
lb_PVKaPM
0.153114
-74.25%
3.88
Malte Skarupke
0.168208
-71.72%
3.54
std::lower_bound
0.594709
+0.00%
1.00
No I was talking about this one:
https://en.algorithmica.org/hpc/data-structures/binary-search/
I hadn’t looked at your code yet due to lack of time. (that’s why the comment that linked to it above doesn’t have a reply yet)
Thanks for doing the comparison, this looks very impressive. I’m very interested how it works and I’ll try to check it out soon. I have been looking for a way to take advantage of instruction-level-parallelism in a binary searches.
I checked the code out now and responded to the comment above. I can reproduce that it’s faster. This one is really neat. I’m having a hard time thinking of ways to further improve it. (for Shar’s algorithm it was easy to spot that it would behave badly for certain sizes, there’s nothing like that for this one)
Great article! Your post drew me into thinking about further ways to optimize the binary search, especially because you noted your version “does more comparisons than std::lower_bound”. How could that be avoided? What would an optimal (comparison-wise) branchless search look like? Well, after some work I came up with an even faster binary search variant: https://mhdm.dev/posts/sb_lower_bound/
How to make it faster: https://www.reddit.com/r/cpp/comments/14okto7/comment/jqf40tp/
Super interesting article. We make heavy use of lookup tables in our project, mostly below 100 elements, and a naive binary search implementation is the same speed as just searching the list.
You can go one step further and actually get the compiler to unroll the loop if you are using fixed sized arrays. You must specify a fixed loop with the below size:
static constexpr size_t steps = std::bit_width( N ) – 1;
This results in one extra comparison sometimes being done on non perfect powers of 2, but compared to the log(N) comparisons/branches it’s worth it for the unrolled loop.
This beats out both naive binary search and linear search by about 4+ times speed (at low N). At higher N the ratio of the binary searches remain the same and as expected the linear search gets left in the dust.
Loop unrolling can work on small tables but loses out when they get larger.
Shar lives in Menlo Park so you could ask him about it.
P.S. By “it” I just mean the history … whether he ever published it or just told Knuth about it, or maybe it was on a mailing list, etc.
I’m having difficulties to compile the following code into anything other than a cmove:
“`
int cmove(int a, int b, bool c)
{
if (c) return a;
return b;
}
“`