Using TLA+ in the Real World to Understand a Glibc Bug
by Malte Skarupke
TLA+ is a formal specification language that you can use to verify programs. It’s different from other formal verification systems in that it’s very pragmatic. Instead of writing proofs, it works using the simple method of running all possible executions of a program. You can write assertions and if they’re not true for any possible execution, it tells you the shortest path through your program that breaks your assertion.
In fact it’s so pragmatic that it even allows you to write your code in a language that looks similar to C.
I recently heard of a bug in the glibc condition variable implementation and since I had used TLA+ before to verify my own mutexes and condition variables, I thought I would investigate. Can you use it to find this bug in real-world complex code? Yes you can, barely, and it wasn’t easy, but it gives me hope that program verification is getting really good and is already able to deal with big and messy code:
The Bug
First lets talk about what the bug is. Here is the link again. The problem is that sometimes pthread_cond_signal() doesn’t do anything. This is part of the pthread implementation of condition variables, which are used to communicate between threads. If thread A tells thread B that it needs to start working on something, then you have to make sure that thread B isn’t sleeping, so you’d use pthread_cond_signal() to wake it up. If the wake-up doesn’t happen, that can easily deadlock a system. (e.g. if thread A later waits for thread B, it will wait forever)
Where is this used? All over the place. Almost all programming languages provide a wrapper for this call, or use it internally to coordinate threads. This probably leads to bugs in lots of C and C++ programs (C++ has a wrapper for pthread_cond_signal() in the standard library) as well as the runtime of at least .NET core, Python, and Ocaml. (according to the comments on that bug)
Now I don’t work on glibc, so I can only perceive that for an outside observer it looks like progress has been slow. The bug was reported in April (but you can find people running into it before that) and since then it’s been mostly silent except for some new comments from a few days ago. I can’t even find a conversation on the mailing list. I suspect that part of the problem is that the code is very tricky and the bug is really hard to understand. And it’s not clear what a fix might look like. A workaround was posted fairly quickly, but it calls pthread_cond_broadcast() which is a heavy operation, so ideally we’d like to avoid that.
One of the benefits of using TLA+ to investigate the bug is that once you can reproduce the bug, it’s easy to try alternative fixes. The bug in question is rare and took years to be uncovered, so how would you know if your fix doesn’t introduce another subtle bug that will take years to discover? With TLA+ you can check all possible code paths through your code, giving you a lot more confidence.
The Primitives: Mutexes, Futexes and Condition Variables
Lets build up our understanding of TLA+ by implementing all the primitives in it.
Mutual Exclusion with a Spinlock
A mutex is a object that ensures that only one thread enters a section of code at a time. If two threads try to enter, the second one has to wait until the first one leaves. The simplest way to do this would be to use a spinlock:
struct bad_spinlock
{
void lock()
{
while (locked.exchange(true))
{
}
}
void unlock()
{
locked.store(false);
}
private:
std::atomic<bool> locked{false};
};
It’s not obvious how this works, but try to think through what happens when two threads call lock() at the same time: exchange returns the old value, so for the first thread exchange will return false and it won’t loop. For the second thread exchange will return true and it will loop until the first thread unlocks the spinlock again. There are many problems with this spinlock, but it works and is good enough to see what TLA+ looks like. Let’s implement it:
--algorithm Spinlock
{
variables locked = FALSE;
procedure lock()
variable old_value = FALSE;
{
exchange:
old_value := locked;
locked := TRUE;
check:
if (old_value)
{
goto exchange;
}
else
{
return;
};
};
procedure unlock()
{
reset_state:
locked := FALSE;
return;
}
fair process (P \in Proc)
{
loop:-
while (TRUE)
{
call lock();
cs:
skip;
call unlock();
};
}
}
This is a lot at once, but it shouldn’t look too crazy. First we declare a global variable “locked”. Then we write the procedure lock() which has a local variable “old_value”. The first thing in the body of the function is a label “exchange:”. The rule for PlusCal (that’s what this language is called) is that any code between two labels is atomic. So the two lines between “exchange:” and “check:” always get executed together. There is no built-in exchange operation, so I implemented my own, storing the old state in old_value and then assigning TRUE to locked. After that I check if the value was already locked and then loop if I have to. Yes, PlusCal has gotos. It also has while loops and we’ll see one below, but here I chose to introduce gotos.
The unlock() procedure is even simpler. I need a label at the beginning of the function because in this language every function has to start with a label. I just call it “reset_state” because that seems like an appropriate name.
Finally we’re adding a “fair process” which is an independent thread of execution. The term “fair” is optional. It means that the process doesn’t randomly stop. You might want to specify code that is robust even if some process randomly stops, but I’m not doing that here so I’m making my process “fair.” The “P \in Proc” gives the process a name, P, which doesn’t really matter, and it says that the name gets chosen from the set Proc, which we will define as a global in a different place. If there are N things in Proc, that means that TLA+ will check all possible interleavings of N processes.
The body of the process starts with a label, which I just called “loop”. The label is outside of the loop body so you might think that we’ll only visit it once, but actually the rules say that we go back to this label after every loop iteration. (to re-evaluate the condition of the while loop)
I put a minus “-” behind the label, which means that this one statement is exempt from the “fair” rule. This means I claim that my code should still work fine if the process stops permanently at that label.
In the body of the loop we just call lock() followed by unlock(), but inbetween we have a label “cs” followed by the statement “skip;”. skip just means that we don’t do anything for this label. The reason for having it is that labels are the places where processes can temporarily pause. So this simulates the fact that in real code this is where your critical section would be, and that critical section might take a while. This label is the reason why our process had to be “fair”: If I was running this with 2 processes, and one of them randomly decided to stop forever at the label “cs”, then we would be deadlocked forever. A “fair” process can wait here for as long as it wants, as long as it doesn’t wait forever.
With this we can write our first assertions. The code above was written in “PlusCal” which is a C-like language that gets translated into TLA+. The assertions actually have to be written in TLA+. TLA+ looks a bit more mathematical and latex-y. (which makes sense because TLA+ is written by the same Leslie Lamport who created latex) Here is the first assertion we’d want to test:
MutualExclusion == \A i, j \in Proc :
(i # j) => ~ /\ pc[i] = "cs"
/\ pc[j] = "cs"
There is a hotkey in TLA+ to convert this to a PDF, giving us nicer formatting:
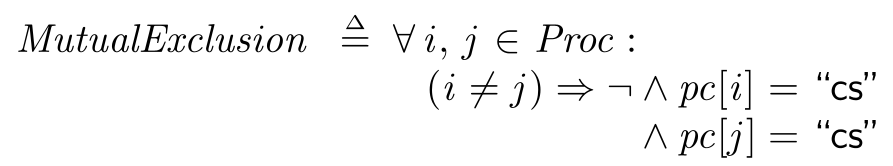
A few things to explain in there: pc[i] = “cs” is a comparison, not an assignment. It means that the process is currently at the label “cs”. The 

So overall this means that for any pair of processes, they can’t both be at the “cs” label.
The second thing that we want to check is that we don’t deadlock. We do that with this assertion:
DeadlockFreedom ==
\A i \in Proc :
(pc[i] = "exchange") ~> (\E j \in Proc : pc[j] = "cs")
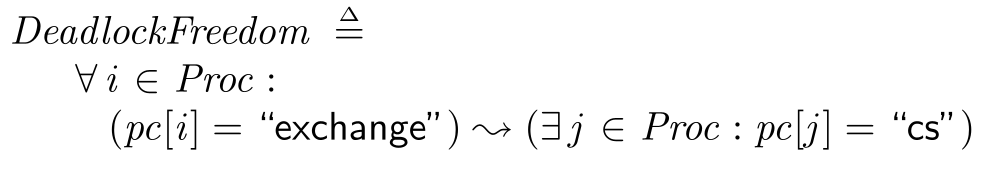
The arrow in the middle of this statement is the important thing. This means that if the thing to its left is true, then at some point in the future the thing on the right will become true. In this case we’re saying that if some process is trying to take the lock, then some process will eventually get into the critical section. Note that we’re not saying it has to be the same process. We can’t promise that with this spinlock. We’re just saying that somebody will eventually get in, and we won’t be deadlocking or busy-looping forever.
The ability to check these temporal properties in TLA+ is one of its most powerful features. We’ll also need this to verify our condition variables later.
With all this in place, we can verify the above statements using TLA+. Running this with two processes, (by assigning a set with two values to Proc) TLA+ finds 36 distinct states that this can be in. All of them fulfill both of our assertions above. More processes find more states, but still no problems.
Now we’re ready to tackle futexes.
Mutual Exclusion with a Futex
The problem with the spinlock is that the waiting thread doesn’t go to sleep. To support this, glibc implements their mutexes using futexes. A futex has two operations: 1. Compare and wait. 2. Wake. The second operation just wakes a thread if it’s sleeping on the futex, the first operation is more interesting. “Compare and wait” means that it will compare the value of the futex to the argument and only go to sleep if they compare equal. It’s easier to explain with an example, so here is a simple mutex implemented using a futex:
struct futex_mutex
{
void lock()
{
if (state.exchange(locked, std::memory_order_acquire) == unlocked)
return;
while (state.exchange(sleeper, std::memory_order_acquire) != unlocked)
{
syscall(SYS_futex, &state, FUTEX_WAIT_PRIVATE, sleeper, nullptr, nullptr, 0);
}
}
void unlock()
{
if (state.exchange(unlocked, std::memory_order_release) == sleeper)
syscall(SYS_futex, &state, FUTEX_WAKE_PRIVATE, 1, nullptr, nullptr, 0);
}
private:
std::atomic<unsigned> state{unlocked};
static constexpr unsigned unlocked = 0;
static constexpr unsigned locked = 1;
static constexpr unsigned sleeper = 2;
};
I’m quite proud of this mutex implementation. It took weeks to make it this small. (the small amount of code also makes it very fast)
You may be wondering what’s special about that atomic unsigned int. Why can we call futex operations on it? The cool thing is that there is nothing special about it. You can call futex operations on anything. It just has to be a pointer to at least 32 bits of readable memory. Now it also becomes clearer what “compare and wait” means: The kernel will compare the memory behind the pointer to the variable that’s passed in, (in my case that’s the constant “sleeper”, with the value 2) and if the memory compares equal, it puts the thread to sleep. The kernel will store the sleeping thread in a hash table, with the pointer address as the key. A wake just looks in the same hash table and if an entry exists, it wakes that thread.
The comparison is crucial to make the above mutex correct. See for example this sequence of behaviors:
| Thread A | Thread B | State |
|---|---|---|
lock() | 0 | |
if (exchange(1)) | 1 | |
lock() | 1 | |
if (exchange(1)) | 1 | |
if (exchange(2)) | 2 | |
unlock() | 2 | |
if (exchange(0) == 2) | 0 | |
futex_wake() | 0 | |
futex_wait(2) | 0 |
The way to read this is that Thread A locks first, then Thread B locks, but before it can go to sleep, Thread A unlocks again, calling futex_wake() too early. In this case the futex_wait(2) at the very end will notice that 2 != 0, and won’t actually put the thread to sleep.
Still there are a lot of possible code paths through this. Especially if we have three or more threads. Consider this start of an execution:
| Thread A | Thread B | Thread C | State |
|---|---|---|---|
lock() | 0 | ||
exchange(1) | 1 | ||
lock() | 1 | ||
exchange(1) | 1 | ||
exchange(2) | 2 | ||
futex_wait(2) | 2 | ||
lock() | 2 | ||
exchange(1) | 1 | ||
unlock() | 1 | ||
exchange(0) | 0 |
So three threads try to enter, and we end up with state=1 at the time of the unlock, meaning thread A will not wake the sleeping thread B. Is this a bug? It’s actually OK because the next thing that thread C does is set state=2, so it will remember to wake thread B after it unlocks.
But it’s hard to think through all the cases, so lets implement this in TLA+. First, lets implement the futex operations:
variables
futex_state = 0;
futex_sleepers = {};
procedure futex_wait(val = 0)
{
check_state:
if (futex_state /= val)
return;
else
{
futex_sleepers := futexes_sleepers \union {self};
wait_for_wake:
await ~ (self \in futex_sleepers);
return;
};
}
procedure futex_wake_all()
{
futex_wake_all:
futex_sleepers := {};
return;
}
procedure futex_wake_single()
{
check_for_sleepers:
if (futex_sleepers = {})
return;
else
{
with (x \in futex_sleepers)
{
futex_sleepers := futex_sleepers \ {x};
};
return;
};
}
Here I chose to implement futexes different from how they’re implemented in the kernel. Mainly because you can’t take the address of a variable in PlusCal. Also we don’t need the full detail. We just need something that works the same way as the real thing. If we wanted to check the correctness of the futex implementation of the kernel, this wouldn’t do. But since we want to check the correctness of something that’s built on top of futexes, we can abstract away the details of futexes.
So how does this actually work? In futex_wait() I take advantage of the fact that all instructions between two labels are atomic. So the work between “check_state” and “wait_for_wake” happens at once. Meaning I can do the comparison and add myself to the sleepers. (the term “self” here refers to the process ID, and \union is how you add yourself to a set) After that we can use the PlusCal keyword “await” to sleep until we’ve been removed again. This is obviously much more complicated in the kernel because C has no “await” primitive. (how would you implement such a keyword? Using condition variables. So good thing we’re looking into that bug in condition variables)
futex_wake_all() is very simple because the language provides the magic “await” keyword. All we have to do is clear the set of sleepers, and the other process will find out automatically. Here we can see how TLA+ was designed to verify this kind of code. It provides magic primitives that are useful for abstracting away the details.
futex_wake_single() is more complicated. First we early-out if nobody is sleeping. Otherwise we use the “with” keyword to pick a random sleeper out of the set of sleepers and remove it. Since TLA+ runs all possible executions of a program, it will actually branch the execution here to continue with all possible values.
With that we’re ready to implement a mutex:
procedure lock_mutex()
variable old_state = 0;
{
exchange_lock:
old_state := futex_state;
futex_state := 1;
check:
if (old_state = 0)
{
return;
};
sleep_loop:
while (TRUE)
{
old_state := futex_state;
futex_state := 2;
sleep_check:
if (old_state = 0)
return;
else
call futex_wait(2);
};
};
procedure unlock_mutex ()
variable old_state = 0;
{
exchange_unlock:
old_state := futex_state;
futex_state := 0;
check_if_sleeper:
if (old_state = 2)
{
call futex_wake_single();
return;
}
else
return;
}
This is where you can see why I like TLA+ so much. It’s a direct one-to-one translation of the C++ code. The only difference is that we’re using the “futex_state” variable from the previous segment instead of giving this its own global variable. I could have also just called it “mutex_state” but it does have to be the same variable, because that’s how futexes work. We can verify that this is correct with the same assertions as above, except that I’m using different labels, so we can replace “exchange” with “exchange_lock” in the assertion DeadlockFreedom. You actually might want to make that check slightly more complicated, but for the details I’ll refer you to the “DijkstraMutex” example that ships with TLA+. For our purposes here, using the existing temporal check is fine. If you’re following along by actually implementing this code, I recommend inserting some intentional bugs to see how TLA+ gives you the shortest execution path that finds a problem. (if TLA+ finds no errors after making a change to the above code, make sure that you didn’t accidentally turn this into a spinlock, which would still satisfy all of our assertions)
One thing we can learn with this mutex implementation is how the number of states likes to explode in TLA+. If I verify my assertions for 2 processes, TLA+ finds 213 distinct states, and finishes running immediately. For 3 processes, TLA+ finds 7013 distinct states and takes 3 seconds to run. Lets make this a table:
| Number of processes | Number of distinct states | Time to verify |
|---|---|---|
| 2 | 213 | 1 second |
| 3 | 7,013 | 3 seconds |
| 4 | 174,233 | 48 seconds |
| 5 | 3,850,245 | 38:16 minutes |
This explosion in the number of states is a common problem when verifying things with TLA+. The method of “try all possible execution paths” explodes quickly, and we’ll have to tweak our models to deal with this. For this mutex, we can run our model checker with 3 processes most of the time, and then we can move up to 4 or 5 processes to double-check once we’re done. (we can also massively reduce the number of states by taking advantage of the symmetry between different processes, but that’s for later)
Finally, lets cover condition variables.
Condition Variables
A condition variable is trying to solve the same problem as a futex: There is some shared variable that I want to check, and if it’s not in the right state, I want to sleep until it is. But condition variables are more general: Where a futex can only compare 32 bits of memory, a condition variable allows you to wait for any condition at all. (in C++ this is expressed as allowing you to pass in a lambda)
The core interface for condition variables is even simpler than that for futexes: It just has the operations “wait” and “wake”. You saw that for futexes the “compare” in “compare and wait” was very important to avoid deadlocks, so how could you possibly make something even simpler? By requiring that condition variables have to always be used together with mutexes, and that you have to follow a specific order of calls. The waiter has to do these steps:
- Lock the mutex
- Check your condition
- If condition was false call pthread_cond_wait(), then goto 2
- Else unlock the mutex
And the waker has to do these steps:
- Lock the mutex
- Change the condition
- Unlock the mutex
- Call pthread_cond_signal
As long as you follow these sequences, “wait” and “wake” are all the operations you need.
One weird thing is that the waiter unlocks the mutex after calling pthread_cond_wait(). Shouldn’t that deadlock because it holds onto the mutex while sleeping? The answer to that weirdness is that pthread_cond_wait() internally unlocks the mutex before sleeping and later re-locks the mutex after waking.
One mistake that everyone makes when they’re first using condition variables is that you come across a place where the step “change the condition” could be atomic. Say it just increments an int. So you think “why is this int-increment protected by a mutex? Let’s use an atomic int instead and get rid of the lock/unlock call.” And by doing that you introduce a deadlock. This is very surprising, but the lock/unlock is there to get the right ordering with the other thread, not to protect “change the condition.” (but you can also use it for that) One fun thing you can do in that case is make “change the condition” atomic and then do step 2 before step 1. Meaning it turns into “change the condition, lock(), unlock(), pthread_cond_signal().” It’s weird that the empty lock/unlock is still necessary, but you can convince yourself by thinking through all possible code paths. On the other hand those details are hard, so it’s best just to follow the normal structure when using condition variables.
We can implement condition variables by using a second futex:
struct futex_condition_variable
{
void wait(std::unique_lock<futex_mutex> & lock)
{
unsigned old_state = state.load(std::memory_order_relaxed);
lock.unlock();
syscall(SYS_futex, &state, FUTEX_WAIT_PRIVATE, old_state, nullptr, nullptr, 0);
lock.lock();
}
template<typename Predicate>
void wait(std::unique_lock<futex_mutex> & lock, Predicate && predicate)
{
while (!predicate())
wait(lock);
}
void notify_one()
{
state.fetch_add(1, std::memory_order_relaxed);
syscall(SYS_futex, &state, FUTEX_WAKE_PRIVATE, 1, nullptr, nullptr, 0);
}
void notify_all()
{
state.fetch_add(1, std::memory_order_relaxed);
syscall(SYS_futex, &state, FUTEX_WAKE_PRIVATE, std::numeric_limits<int>::max(), nullptr, nullptr, 0);
}
private:
std::atomic<unsigned> state{0};
};
This code is inspired by this implementation.
This follows the C++ naming convention where notify_one() == pthread_cond_signal() and notify_all() == pthread_cond_broadcast(). The other thing to note is that we provide two implementations of wait: One of them is just a convenience wrapper that allows you to pass in a predicate for the “check the condition” step, doing the looping correctly for you.
The semantics of this are pretty simple because the mutex and the futex do most of the work for us. The only extra thing we have to do is make some change to the state variable in the notify() functions to ensure that a concurrent waiter doesn’t fall asleep, missing the wake call. It doesn’t matter what we change because we just have to make sure it doesn’t compare equal to “old_state.” Adding 1 seems good because that way it’s going to be a long way until it wraps around. We could get an ABA problem if this wraps around too quickly, but it seems very unlikely to get 4 billion calls to notify() in the same time as one call to wait().
Lets write this in PlusCal:
variables
mutex_index = 0;
cv_index = 1;
futexes = [i \in {mutex_index, cv_index} |-> [state |-> 0, sleepers |-> {}]];
procedure futex_wait(index = 0, val = 0) { ... }
procedure futex_wake_single(index = 0) { ... }
procedure futex_wake_all(index = 0) { ... }
procedure lock_mutex() { ... }
procedure unlock_mutex () { ... }
procedure cv_wait()
variable old_state = 0;
{
cv_wait_start:
old_state := futexes[cv_index].state;
call unlock_mutex();
cv_wait_sleep:
call futex_wait(cv_index, old_state);
cv_wait_relock:
call lock_mutex();
return;
};
procedure cv_signal()
{
cv_signal_start:
futexes[cv_index].state := futexes[cv_index].state + 1;
call futex_wake_single(cv_index);
return;
};
procedure cv_broadcast()
{
cv_broadcast_start:
futexes[cv_index].state := futexes[cv_index].state + 1;
call futex_wake_all(cv_index);
return;
};
Since we now have two futexes, I had to change the interface of futex_wait() and futex_wake_single(). We now have a global map/dictionary of futexes. We have two indices for this: mutex_index = 0, and cv_index = 1. Behind each of them is another map with the “state” and “sleepers” variables that we had before. I had to change the implementation of all previous procedures, but it’s just search/replace so I’m not showing it. The uses of “futex_state” in lock_mutex() and unlock() were replaced by “futexes[mutex_index].state,” with similar changes in other places.
The implementation of cv_wait() and cv_signal() are once again a very mechanical translation from C++. However we have a problem here. TLA+ wants to explore all possible states, and with our counter we have infinitely many states, because you can always add + 1 to the counter to get a new state. We could make the counter wrap around, but then TLA+ will immediately find the bug that if the counter wraps around, we’ll miss a wake-up. (e.g. if we wrap the counter at 16, TLA+ will find the interleaving where cv_wait() gets called once, and before it finishes cv_signal() gets called sixteen times) But that bug will never happen in practice.
This is a bit tricky to solve, but for now we can just limit how many signals we emit. We could write our process to just call cv_signal() three times, and then stop forever. If there is a bug that only happens if we call cv_signal() four times, we wouldn’t find that bug, but we’ll just have to hope that that doesn’t happen. (famous last words) Speaking of the processes, how do we test a condition variable? The old “lock->cs->unlock” test doesn’t make sense any more. Let me start with the code:
variables
work_to_do = 0;
num_work_started = 0;
work_done = 0;
all_done = {}
procedure add_work()
{
add_work_start:
call lock_mutex();
generate_work:
work_to_do := work_to_do + 1;
num_work_started := num_work_started + 1;
call unlock_mutex();
notify_worker:
call cv_signal();
return;
};
procedure broadcast_all_done()
{
generator_all_done:
call lock_mutex();
notify_all_done:
all_done := all_done \union {self};
call unlock_mutex();
broadcast_all_done:
call cv_broadcast();
return;
};
fair process (GeneratorProc \in GeneratorProcs)
variable num_loops = MaxNumLoops;
{
generate_work_loop:-
while (num_loops > 0)
{
num_loops := num_loops - 1;
call add_work();
};
call broadcast_all_done();
}
fair process (WorkerProc \in WorkerProcs)
{
work_loop:
while (TRUE)
{
call lock_mutex();
wait_for_work:
while (work_to_do = 0 /\ all_done /= GeneratorProcs)
{
call cv_wait();
};
take_work:
if (work_to_do /= 0)
{
work_to_do := work_to_do - 1;
call unlock_mutex();
}
else
{
call unlock_mutex();
goto worker_done;
};
do_work:
work_done := work_done + 1;
};
worker_done: skip;
}
Starting from the top, we have four new variables. The procedures “add_work” and “broadcast_all_done” follow the four steps that the waker has to do exactly: 1. Lock 2. modify condition 3. unlock 4. signal. I have two different pieces of logic to test both cv_signal and cv_broadcast.
The new GeneratorProcess then just calls add_work in a loop before shutting down.
The WorkerProcess is more complicated, but it also follows the four steps that I outlined above exactly:
- Lock
- Check condition
- If false, wait and goto 2
- Else unlock
The condition in this case is either that there is work to do, or that all GeneratorProcesses have added themselves to the “all_done” list. (remember that the /\ operator is the “boolean and”) We use one condition variable for both conditions, so that we can wake up and shut down correctly.
“take_work” then checks which of the two cases we have fallen into, and if there is work to do, it consumes one item of work.
Finally, in “do_work” we just record that we did work. This is obviously a very simplified view of the work, but it’s enough to test if the condition variable implementation works.
Finally we need new assertions to test if this code is correct. I landed on these three:
WorkGetsTaken == work_to_do > 0 ~> work_to_do = 0
WorkGetsDone == <>(num_work_started = work_done)
AllFinish == all_done = GeneratorProcs ~> (\A i \in (WorkerProcs \union GeneratorProcs) : pc[i] = "Done")

The first one asserts that any time that work_to_do is greater than 0, some process will take the work and bring it back down to 0. This would break if our “cv_signal” function had a bug in it, causing a waiter to not wake up.
The second one asserts that we’re not dropping any work accidentally. The operator <> means “eventually”. So this asserts that we always eventually end up in a state where “work_done” is equal to “num_work_started”. This would fail if we had a deadlock somehow.
The last one asserts that the broadcast at shutdown works correctly. If all GeneratorProcs have added themselves to the “all_done” set (just checking for set equality here) then we assert that at some point in the future all threads will finish running. I’m checking for the “Done” state, which is a special, buit-in state that a process goes to if it reaches the end of its body.
Running this with one generator, two workers and MaxNumLoops=3 finds 267,171 states, which takes 53 seconds to validate. Let’s make a table again:
| Num Generators | Num Workers | signal() calls | Distinct States | Time |
|---|---|---|---|---|
| 1 | 1 | 4 | 6,771 | 3 seconds |
| 1 | 2 | 3 | 267,171 | 53 seconds |
| 2 | 1 | 3 | 1,286,732 | 3:54 minutes |
| 2 | 2 | 2 | >16,000,000 | >2 hours (I canceled) |
So this clearly explodes in complexity quickly, and running this on any kind of large number of workers or generators just never finishes, even though I kept on decreasing the number of loops. One possible solution is that TLA+ can take advantage of symmetry between processes. I don’t actually know the exact semantics of that, but I think the idea is that since all my workers are running the exact same code, and none of their logic depends on their ID, TLA+ can deduplicate a bunch of states. E.g. we’ll get the same behavior if process 1 takes the first piece of work or if process 2 takes the first piece of work. Here is the same table with symmetry enabled. (only within workers, and within generators, not across the two groups)
| Num Generators | Num Workers | signal() calls | Distinct States | Time |
|---|---|---|---|---|
| 1 | 1 | 4 | 6,771 | 3 seconds |
| 1 | 2 | 3 | 135,266 | 32 seconds |
| 2 | 1 | 3 | 647,440 | 2:21 minutes |
| 2 | 2 | 2 | 7,158,146 | 50:24 minutes |
This is a little better, so with that lets finally move on and work on the real code, the glibc implementation of condition variables. Sure, it’ll be a bit more complicated, but how bad can it be?
Glibc Condition Variables
The condition variables in glibc are much bigger than the simple code I posted above. I don’t actually know the reason for that. I know the current implementation is a result of a complete rewrite in 2016 because they couldn’t solve a bug in the old implementation, which was also quite complex. (including requiring custom linux kernel changes in the form of the FUTEX_CMP_REQUEUE flag) The bug had to do with waking up threads that went to sleep after a wake. Meaning if you had N threads sleeping, then called signal() N times, then put M more threads to sleep, you could get a bug where only N-1 threads from the first group woke up, and one thread from the second group. So one thread from the second group stole a signal from the first group. The consequence of that was that a signal at time t can wake up a thread that goes to sleep at time t+1. I think my implementation above does not have this bug, but it depends on the implementation of futexes in the kernel. If they have this bug, then my implementation has, too. Maybe that’s why the glibc implementation is so big, it doesn’t trust the ordering of the kernel.
In any case I made a collage of all the code that we have to implement in TLA+:

You can click on it if you want to actually see the code. In their defense, most of this is comments, but even if we remove those we still have a problem. As a proxy for how complex this is: This uses six futexes. (seven if you count the one in the required mutex)
What does this do? This wants to ensure that a call to wait() can not be woken up by a call to signal() that has already finished in the past. To do this it has two groups of sleepers, called g1 and g2. signal() always wakes up sleepers in group g1, and wait() always adds sleepers to g2. When g1 is empty, the next call to signal() will switch g1 and g2.
One problem with that idea is that we can’t ask the kernel how many threads are sleeping in g1 and g2. The futex interface doesn’t provide that information. So this has to keep its own count. And that’s where this gets complicated. I actually don’t fully understand all the counts, but there are at least four: The number of waiting threads, (wrefs) the number of sleepers per group, (g_refs) a second count for the number of sleepers per group, (g_size) and the number that are allowed to wake up in each group. (g_signals)
The bug happens when a sleeper takes a while to wake up, and another thread keeps on calling pthread_cond_signal(). If the calls to signal() manage to switch g1 and g2 twice in the time that it takes one thread to wake up, it might think that it belongs to the current group, even though the groups have moved on. In that case the counts can get messed up, so there is some careful logic to try to detect this case and to try to fix things. And that fix-up code has a subtle bug.
I tried understanding the bug based on the comments in the bugtracker, but they’re just guessing and with the complexity of the code, I have no chance of understanding what’s going on. So can we reproduce this in TLA+?
The biggest problem is how much code there is, so to start off I cut everything that we didn’t strictly need: Support for timeouts and shared memory, support for thread cancellation, a spin-wait optimization, all mentions of memory orderings, LIBC_PROBE and other things I’m probably forgetting, but I just wasn’t making a dent. Unfortunately most of this code would be needed if I wanted to reproduce the bug in TLA+.
Luckily translating the code from C to PlusCal was mostly straightforward. The biggest changes I had to make were because PlusCal doesn’t have support for returning values from functions. So I chose to inline all the smaller functions and use global variables to return the result of condvar_quiesce_and_switch_g1. Below is a similar collage of the resulting code. It’s basically the same amount of code, except that there are no comments. Since it’s a one-to-one translation, I can easily switch between the PlusCal code and the C code to read the comments there. Once again I’m just trying to give you a feeling for the volume of code and I don’t expect you to read it, that’s why it’s a picture:

After I got some initial translation-errors sorted out, this didn’t actually run too badly. I ran with 1 generator, 2 workers, and 2 signal calls, and TLA+ finished in less than an hour, finding no bugs. I wasn’t too surprised that it found no bugs, because for the problematic code to run, you need to close at least 2 groups, meaning I have to send two signals and then also send a third one to trigger the bug. Unfortunately when I switched to 3 loops, that uncovered so many additional states that this ran all night and still didn’t finish.
In his introduction videos for TLA+, Leslie Lamport mentions that abstraction is very important. We need to focus on the parts of the specification that we care about and abstract away the rest. I already did that in my futex implementation above, which is much simpler than the actual futex implementation in the kernel. There are two other clear candidates for simplification in this code: 1. The mutex, 2. A second, internal mutex inside of the CV. The second one is very similar to the normal mutex, but it uses two bits of a variable that’s also used for other purposes, so it has to be careful to not accidentally change the other bits. (see the functions condvar_acquire_lock() and condvar_release_lock()) To simplify the algorithm I replaced both of these with very simple spinlocks. For the purposes of finding our bug, we’ll just assume that the mutexes work correctly and don’t need to be simulated in full detail.
I also removed the num_work_started variable and made work_done a boolean. I could write almost the same assertions without keeping a count. And finally I went through the code and removed as many labels as I could without changing the behavior. The reason why the number of states explodes in TLA+ is that for every new label, TLA+ will try all possible states for all other processes. This means that the amount of work grows exponentially with the number of labels.
After those simplifications I was finally able to run the code with 3 calls to signal(), and it took just 13 minutes. That’s the thing about optimizing code with exponential slowdown: optimizations also give you exponential speedup. A small amount of work changes the same code from taking half a day to taking 13 minutes. But I still found no bug.
Turns out you need 4 calls to signal() to reproduce the bug, which I was now able to do since I had faster code. (it took 1:05 hours) The shortest path that TLA+ found took 209 steps, after which both workers were sleeping on the condition variable even though there was still work to do. 209 steps may not sound like much, but when I clicked through the 209 states, it was quickly hard to follow what the state of the condition variable was and when it went wrong.
Detailed Walkthrough of the Order of Events
Next I had to figure out what I had found. Is it actually the same bug? And if it is, is the theory from the bug description correct? Since I’m about to show you a long table, I’ll let you know ahead of time that the answer is yes, this is the original bug. This table describes the shortest order of events to make the bug happen:
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *add work* | ||
| *take work* | ||
| *do work* | ||
| *try to take work again* | ||
| call cv_wait() | ||
| set wrefs = 8 | ||
| g = 0 | ||
| call cv_signal() |
Let me interrupt here to explain how this works. This is just the first few steps, the table will continue below. The way to read this is that first the Generator process adds one unit of work. The first worker thread immediately takes that work, finishes it, and waits for the next unit of work. All this before the Generator process had time to signal that it added work. The last step in this table is that the Generator calls cv_signal() to signal that it added work, even though that work is already finished. So already we’re in a weird state, where the signal will allow a process to wake up even though there won’t be work for it. That’s not the source of the bug, just a introduction for the kinds of interleavings that TLA+ explores. Up to now Worker process 2 hasn’t done anything, but it will jump into action soon.
I skipped over most variable assignments, except for two: setting wrefs to 8 tells the condition variable that somebody is sleeping on it. The process hasn’t gone to sleep yet, but without this assignment, the generator process would early-out in the cv_signal() call that it’s about to do. The second variable is “g = 0” which lets us know that Worker process 1 is looking for a signal on group 0 of the condition variable.
Also, just to clarify I am sometimes combining many steps into one. The *add work* line actually consists of seven steps. Looking at every single step just makes this more confusing. With that, lets continue. This is the next row of the same table:
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| check for waiters (wrefs >= 8) | ||
| unlock_mutex() | ||
| lock_mutex() | ||
| cv_wait() | ||
| quiesce_and_switch_g1() | ||
| g = 1 | ||
| g_signals[0] = 2 | ||
| g_signals[0] = 0 | ||
| futex_wake() | ||
| return from cv_signal() | ||
| unlock_mutex() |
At this point cv_signal() has finished. The signal was immediately consumed by Worker 1, who was just about to go to sleep, but then found that a signal was ready to consume. The call to futex_wake doesn’t actually wake anyone. Worker 2 has only just started it’s call to cv_wait(), getting far enough to unlock the mutex. It’s looking for a signal on group 1.
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *add work* | ||
| call cv_signal() | ||
| quiesce_and_switch_g1() | ||
| g_signals[1] = 2 | ||
| g_signals[1] = 0 | ||
| return from cv_signal() | ||
| *add work* | ||
| call cv_signal() | ||
| *do work* | ||
| *take work* | ||
| *do work* | ||
| cv_wait() | ||
| call quiesce_and_switch_g1() | ||
| unlock_mutex() |
At this point the setup for the bug is done, but nothing is wrong yet. Worker 1 is still not quite finished with cv_wait(), and in the meantime the Generator process and Worker 2 have generated and finished enough work that the active group has switched all the way back to group 0, the one that Worker 1 thinks it is in. Still nobody has ever actually gone to sleep on a futex. But now Worker 1 is about to get to the end of cv_wait(), where it will hit a rarely used code-path which starts with this comment: “We consumed a signal but we could have consumed from a more recent group that aliased with ours due to being in the same group slot.” Meaning this code path is supposed to handle the case when the group has wrapped around like this.
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *still in quiesce_and_switch_g1()* | ||
| *undo steal* g_Signals[0] = 2 | ||
| futex_wake() *done with undo steal* | ||
| lock_mutex() | ||
| *check for work* | ||
| cv_wait() | ||
| unlock_mutex() | ||
| g_size[0] = 2 | ||
| g_signals[0] = 0 | ||
| return from quiesce_and_switch_g1() |
Now we’re in a buggy state. I don’t fully understand all of this state myself, but here is my best attempt at an explanation: Worker 1 thought it stole a signal, so it wanted to wake one person sleeping on the futex. But nobody ever went to sleep in this entire trace, so all it did was increment g_signals. This would normally just lead to a spurious wakeup, which are allowed, but at the same time the Generator process was still in quiesce_and_switch_g1(). That function sets g_size[0] to 2, which means that at that time there are two processes sleeping in group 0. This will be wrong, because immediately after that, Worker 2 consumes the signal from Worker 1, which will cause it to finish cv_wait. (once again without actually having gone to sleep)
So now Generator thinks that there are two threads in cv_wait() when actually there is only one thread in cv_wait(). After finishing quiesce_and_switch_g1(), we are still inside of cv_signal(), so next we will do the work of that function, waking one process:
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *still in cv_signal()* | ||
| g_signals[0] = 2 | ||
| g_size[0] = 1 | ||
| futex_wake() | ||
| g_signals[0] = 0 | ||
| cv_wait() | ||
| cv_wait() | ||
| futex_wait(g_signals[1]) | ||
| *add work* | ||
| cv_signal() | ||
| g_signals[0] = 2 | ||
| g_size[0] = 0 | ||
| futex_wake(g_signals[0]) | ||
| futex_wait(g_signals[1]) |
And finally we’re deadlocked. In the first two rows Generator increases g_signals[0], allowing Worker 1 to finish cv_wait(). It also decreases g_size[0] to remember that there is one fewer sleeper on group 0. There is still no additional work to do, so both Worker 1 and Worker 2 loop and call cv_wait() again. This is the first time that they actually go to sleep, sleeping on g_signals[1].
At the same time Generator is adding one more unit of work. Unfortunately g_size[0] is still positive, so it doesn’t call quiesce_and_switch_g1(). This means that it tries to signal to g_signals[0], where nobody is sleeping. So nobody receives this message, both workers are sleeping in the other group, this work never gets done, and we are forever deadlocked.
Analyzing the Bug
So what went wrong? The problematic special case was supposed to handle when we stole a signal from another sleeping process, but in our trace no process ever went to sleep until the very end, when we deadlocked. And if nobody is sleeping, the adjustment of g_signals will be inconsistent with g_size. We will think two threads are still sleeping, when actually one was allowed to early-out. Rereading the first comment of the bug description, I think this is exactly the scenario that it describes. So we can confirm that the bug description describes the right problem, and the above trace describes the shortest sequence of events that lead to it.
Unfortunately this still doesn’t tell us how to fix the bug. This is still incredibly complex and it’s still hard to predict what effect potential changes would have.
But we can try potential solutions in TLA+. The first one I tried is the patch from the bug report: Just call cv_broadcast() in the stealing case. I can verify that it fixes the bug: As soon as I run with it, TLA+ finds no more problems. But it doesn’t do so for the reason explained in the patch. The patch says that this will cause all waiters to spuriously wake up, but in my trace above nobody was waiting on the condition variable when the state went wrong. Instead it fixes the problem for a simple reason: cv_broadcast() essentially resets the state of the condition variable. So that gives us a hint that one potential solution might be to reset the state in a cheaper way.
Another thing I tried is to simplify the “potential stealing” case. The “fix stealing” branch is essentially a partial, incorrect, reimplementation of cv_signal(). So I tried to just call cv_signal(), which shouldn’t have the same bug, and should be cheaper than calling cv_broadcast(). Unfortunately this deadlocks more quickly. I didn’t look into why.
Understanding Stealing
At this point I was thinking that I still don’t fully understand the code. So I decided to try to find out what this “potential stealing” case was actually intended to solve. TLA+ makes that easy: I just remove the code and see what breaks. I get a trace that deadlocks in 150 steps, which is still a lot of steps, but slightly better than before. Unfortunately I’ll need to create a second table to explain. I’ll try to compress it even more than above:
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *add work* | ||
| *take work* | ||
| *do work* | ||
| g_signals[0] = 2 | ||
| cv_wait() | ||
| *notice that g_signals[0] != 0* | ||
| *add work* | ||
| *take work* | ||
| *do work* | ||
| cv_wait() |
The start is similar to before. The generator generates two pieces of work, both of which are consumed and finished before it has a chance to signal for them. Both workers immediately call cv_wait() again, looking for more work. Worker 1 hasn’t actually gone to sleep and is just about to consume the one signal that Generator has created, by doing a compare_exchange with g_signals[0] in order to early-out of cv_wait(). But first Generator will signal that it has added a second piece of work:
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| quiesce_and_switch_g1() | ||
| *close group 0* g_signals[0] = 0 | ||
| g_signals[1] = 2 | ||
| g_signals[1] = 0 | ||
| cv_wait() |
When generator signals, it notices that there is nobody waiting on group 0. You might think that Worker 1 is sleeping, but it’s in a state where it wanted to early-out of cv_wait(), and never incremented g_refs. So the group gets closed and Worker 1’s compare_exchange won’t succeed. Not that it’s gotten there yet… Meanwhile Generator finally manages to signal that it has added a second piece of work, and Worker 2 immediately consumes that signal, in what’s called a “spurious wake,” because it got woken even though there is no extra work to do. (because it finished the available work before the signal got emitted) It immediately calls cv_wait() again.
| Generator | Worker 1 | Worker 2 |
|---|---|---|
| *notice that* g_signals[0] = 0 | ||
| *stop loop* | ||
| cv_broadcast() | ||
| quiesce_switch_g1() | ||
| g_signals[0] = 2 | ||
| futex_wake_all() | ||
| All Done | ||
| g_signals[0] = 0 | ||
| All Done | ||
| futex_wait(g_signals[0], 0) |
And these are the last steps for our deadlock. Generator decides to generate no more work and broadcast that it’s all done. (I didn’t show this option in my PlusCal code above. Pretend I ran with MaxNumLoops=2) Worker 1 finally gets around to doing the compare_exchange that it wanted to do to early out. Worker 2 finally calls futex_wait(g_signals[0], 0) and goes to sleep forever.
Where is the bug? Worker 2 wasn’t supposed to go to sleep, because g_signals[0] was supposed to be 2. So the “compare” part of the “compare and wait” of the futex should have returned false. But Worker 1 came back from the past and did a decrement of g_signals that should have belonged to a previous generation. This is what the “potential stealing” code was supposed to protect against. TLA+ immediately found the problem once I removed that code.
With this we can also understand the suggestion Georgy Kirichenko posted on the bug report a few days ago: He suggested to squeeze info about the rotation of groups into g_signals, so that the compare-exchange from the past would have failed.
But armed with this trace I wanted to try another solution: What if we made it impossible for Generator to close group 0 when Worker 1 is just about to compare_exchange on it? The reason for this idea is that there is already very similar logic in quiesce_and_switch_g1(). That function will wait for all sleeping processes in the old group to wake up before proceeding. Unfortunately Worker 1 didn’t register itself as a sleeper, because it first wanted to try to early-out. We should be able to fix the bug by making Worker 1 register itself as a sleeper before it tries to early-out. It’ll be a bit slower, but speed is not the priority right now. After all it’s easy to be fast when you’re wrong.
As soon as I make that change the problem goes away. And we also no longer need the special case for “potential stealing” of a signal, allowing me to remove a big code block. There is also a hint for how to not affect performance: After moving the increment of g_refs, it’s right next to the increment of wrefs. And now the decrement of g_refs is right next to the decrement of wrefs. So these two variables count almost the same thing now, and maybe we can get rid of wrefs. Then this would actually end up being cheaper than before. That change needs more work to verify though, because wrefs is used in pthread_cond_destroy, which I’m not simulating here. So I’ll just leave this as a suggestion to the people who will actually fix the bug. It should be possible to verify that change in TLA+ as well, but this blog post is already massive, and I had to end somewhere.
Conclusions
What have we learned? We learned that TLA+ is good enough to verify complex real-world code. I don’t want to paint an overly rosy picture, because it did constantly feel like I was right up against the limit of what TLA+ can do. I always had to pay attention to not make the number of states explode. And I had the benefit of knowing which bug to look for.
But I have a lot of faith in the model of TLA+. When I used this before to verify my own condition variables and mutexes, it was uncanny how quickly TLA+ would zero in on any problems I had. After you experience how thorough it is in taking your code apart, you will have a lot of faith in your code when it finally runs without problems. At the point in the blog post where I said “lets find out what the stealing code is for by removing it,” that’s literally what I did. And I had full faith that TLA+ would immediately tell me where the problem was if I removed that code. Think of how powerful that is. Don’t you wish you were programming in a system where if you removed some code, and if that created a problem, you could be confident that the system would find out for you, and would produce the shortest possible execution that illustrates the problem?
When I said that I had the benefit of knowing which bug to look for, that is only relevant because I was right at the limit of what I can run in TLA+. I’m certain that TLA+ would have found this bug easily if I didn’t have to worry about running the smallest number of Generators, Workers and MaxNumLoops. And if you’re verifying simpler code, you won’t have to worry as much.
I also like that TLA+ provides PlusCal, which is close enough to C that you can translate from it to C++ without re-introducing bugs. (except that you have to get your memory orderings correct. TLA+ doesn’t model those)
So it is very good at these things, and I personally would never write any synchronization primitives or protocols without verifying them using TLA+.
So what are the biggest problems? Exploring long traces is definitely not fun right now. I had to create long tables manually to understand the problems. (I simplified them for the blog post) It would be very helpful if TLA+ could generate those tables automatically.
Another big problem is how easy it is to make the number of states explode. The glibc condition variable has a similar counter (wseq) internally as my simple condition variable above. Those counters are poison in TLA+. Because after it finishes exploring all states for the value “wseq=4” it will then go and explore all the same states again for the value “wseq=6”. I had a similar problem with the “work_to_do” counter. Maybe I just don’t know of a trick that helps with those. But if we could wrap the counters, I could turn my limited loops into infinite loops and have more confidence that all possible states are explored.
All that being said, hopefully I showed you how to live with the current shortcomings, and how TLA+ makes it possible to check code that looks pretty close to the original code.
As a final point: One commonly named benefit of TLA+ is that it allows you to simplify your code. Once you’ve written all the assertions that you require from your model, it’s easy to test if those assertions still hold after a change. (like removing an “if” statement that shouldn’t be needed but is still there “just in case”) I mentioned above that one potential fix for the bug is to broaden the scope of g_refs, and how that might make wrefs unnecessary. I am certain that that could be verified with TLA+. Similarly the glibc implementation is complex because it wants to guarantee certain orderings. I think those ordering guarantees can also be expressed using the temporal properties in TLA+. If that is the case, then we can check if the simple condition variable that I posted here has the same guarantees. I have a hunch that it does, and that glibc could be simplified a lot. Would I make those changes in the C code? No, it’s too scary. Would I make them with the help of TLA+? Definitely, and with confidence.
All TLA+ code from this blog post is uploaded here. All code snippets in this blog post are copyright (C) Malte Skarupke 2020 using the MIT License.

That’s very impressive. Are you going to report on your work to the bug tracker or to the glibc mailing list?
Yep, I just left a comment. I didn’t quite finish all the work I was going to do before publishing the blog-post, because I had to hit my self-imposed deadline of still posting in October.
So I left the comment a bit late.
Great. Thank you very much!
Nice work! This is a great worked example of TLA+’s application to a meaty real world problem.
One question I have is the reasoning for having 2 groups in the implementation; what actual correctness problem is this trying to solve vs just having one group?
”
This wants to ensure that a call to wait() can not be woken up by a call to signal() that has already finished in the past. To do this it has two groups of sleepers, called g1 and g2. signal() always wakes up sleepers in group g1, and wait() always adds sleepers to g2. When g1 is empty, the next call to signal() will switch g1 and g2.
”
hints at an answer but seems like worst case this will be only a spurious wakeup (which you have to handle anyway).
The problem was a stolen wakeup. E.g. this sequence:
A: wait();
B: wait();
C: wait();
D: signal(); signal(); signal();
E: wait();
F: wait();
G: wait();
We’d expect that at the end, A, B and C are woken up, and E, F and G are sleeping.
But if E can get accidentally woken up by one of the signal() calls that finished just before it ran, then it might steal that signal. It’s no problem for E to be spuriously woken up, but it is a problem if A, B or C stay asleep.
So if we end up with A, B, E woken up, and C, F, and G sleeping, that’s not allowed.
This is my best understanding of the bug with the old glibc implementation, and why the current glibc implementation has two groups of sleepers.
Oh and just to be double-clear: In this sequence the only requirement is that all of A, B and C get woken up at least once. We have no requirements on E, F and G. They can be woken up spuriously, or they can stay asleep.
Even in this example, supposing all threads A to G were running concurrently, why should we expect the signals from D to only affect A to C? Unless some out of band (not given in the example here) happens before relations are established, namely the following:
1) D’s last signal happens before E calls wait()
2) D’s last signal happens before F calls wait()
3) D’s last signal happens before G calls wait()
I would not expect D’s signals to only apply to A to C unless all of the 3 relations are established out of band.
Looking at the man page https://linux.die.net/man/3/pthread_cond_signal I don’t see anything guaranteeing any kind of FIFO wakeup where the signals are guaranteed to wake up threads in the order that they happened to call wait (note: there is a total order for all wait calls because you can only call wait() while holding the lock).
Yep, to clarify what I meant is that the calls happen in order, not concurrently. Meaning first A calls wait(), then B calls wait(), then C calls wait(), then D calls signal() three times. Then at some later point E, F and G also call wait().
You have to hold the lock while calling wait(), so we can be sure that thread A, B and C happen one after another. For ease of argument, lets say that thread D also holds the lock while calling signal() three times, so we can be sure that threads E, F and G can’t cut in.
In that sequence we have to guarantee that A, B and C are woken up. We don’t care in which order A, B and C are woken up. But since we got three calls to signal(), and three threads are sleeping, all three have to be woken up.
If at some later point thread E tries to go to sleep, it’s not OK for it to steal the signal and to prevent thread C from waking up.
(This is a continuation from the thread above; cant seem to find a reply button for the last comment in the chain. Is comment depth limited somehow?)
I agree with what you said, in this case A, B, and C should be guaranteed to be woken up.
However, the reasoning for having two groups is still unclear. The implementation that you gave of condition variables (futex_condition_variable) seems to guarantee prevention of this stolen wakeup problem and it only uses one “group”. This seems to be an existence proof that multiple groups are not necessary.
Essentially the question that I am trying to answer is
“How can the use of multiple groups in the glibc implementation of condition variables be justified?”
Given that there was a bug that escaped testing and actually impacted real users, it seems prudent to remove pieces of the implementation that are not strictly necessary (reduce state space, make code easier to reason about, model check, test, etc)
Yes, comment depth is limited. But you can click “reply” on the parent post.
The futex_condition_variable that I posted above is my own work, so they couldn’t have been aware of that. But it is heavily inspired by the LocklessInc article about futexes which I linked right underneath. That article is not dated, so I don’t know how old it is, but if it’s older they maybe could have been aware of that one.
I don’t know the answer to your question, but there could be many reasons. Like maybe mine has some unexpected performance problems (e.g. I don’t have a spin-wait optimization like they do) Or maybe they just didn’t think it could be done more simply. I know that when I decided to write my own condition variables, my first efforts were all incredibly complex. Before I saw that LocklessInc article, I also wouldn’t have thought that condition variables can be that simple.
For the sake of consistency would you consider rewriting
as…
syscall(SYS_futex, &state, FUTEX_WAKE_PRIVATE, locked, nullptr, nullptr, 0);?No that number indicates how many threads should be woken up. So it means that I want to wake up 1 thread. It’s unrelated to the “locked” constant.
“Exploring long traces is definitely not fun right now.”
Same. It takes a very long time every with traces which could seem small (as you explained) in absolute value. Binary searching through the trace to find out when the bug occurred isn’t fast and understanding why it happened, given the previous execution steps, is no sinecure either.
You said “I had to create long tables manually to understand the problems.”
If you still have some scribbled notes of that (I assume many pages), I think it could be valuable to post a picture somewhere even (doesn’t have to be legible). Just so that people can appreciate how much work it is.
That was a hell of a post, thank you so much. Out of curiosity, how much time did you spend on this exploration? (blog writing time aside)
The Toolbox’s integration [1] of interactive communication graphs [2] is, perhaps, a useful supplement to the (manually created) tables.
By the way, symmetry reduction should not be used when checking liveness properties (see Specifying Systems for details).
[1] https://github.com/tlaplus/tlaplus/issues/267#issuecomment-535308134
[2] https://cacm.acm.org/magazines/2016/8/205044-debugging-distributed-systems/fulltext
Thanks for the informative post! Not sure if you’re aware, but there’s a spam site that just copied this post word-for-word and is re-hosting it under a different author’s name. I don’t want to link to them because I don’t want to give them any more traffic, but they come up as the first or second option on DuckDuckGo and Qwant. Just thought you ought to know.
Thanks for letting me know. Helpfully that website has a page explaining how to send them a DMCA takedown notice. They must be doing this a lot… I sent them one, we’ll see what happens. What a waste of everyone’s time.
It took until 2025, but the issue was finally closed as fixed in January