plalloc: A simple stateful allocator for node based containers
by Malte Skarupke
Allocators in C++ are awkward classes. Allocators are usually zero size to make the containers small, and they have no state because that used to be difficult to do in C++. But nowadays we don’t really care about the size of our containers (we care about the size of the content of the containers) and since C++11 we have support for stateful allocators.
The problem I’m trying to solve is that node based containers have bad cache behavior because they allocate all over the place. So I wrote a small allocator which gives out memory from a contiguous block. It speeds up std::map and std::unordered_map. It’s called plalloc because I think this is a pool allocator.
Code is below:
#pragma once
#include <memory>
#include <vector>
template<typename T>
struct plalloc
{
typedef T value_type;
plalloc() = default;
template<typename U>
plalloc(const plalloc<U> &) {}
plalloc(const plalloc &) {}
plalloc & operator=(const plalloc &) { return *this; }
plalloc(plalloc &&) = default;
plalloc & operator=(plalloc &&) = default;
typedef std::true_type propagate_on_container_copy_assignment;
typedef std::true_type propagate_on_container_move_assignment;
typedef std::true_type propagate_on_container_swap;
bool operator==(const plalloc & other) const
{
return this == &other;
}
bool operator!=(const plalloc & other) const
{
return !(*this == other);
}
T * allocate(size_t num_to_allocate)
{
if (num_to_allocate != 1)
{
return static_cast<T *>(::operator new(sizeof(T) * num_to_allocate));
}
else if (available.empty())
{
// first allocate 8, then double whenever
// we run out of memory
size_t to_allocate = 8 << memory.size();
available.reserve(to_allocate);
std::unique_ptr<value_holder[]> allocated(new value_holder[to_allocate]);
value_holder * first_new = allocated.get();
memory.emplace_back(std::move(allocated));
size_t to_return = to_allocate - 1;
for (size_t i = 0; i < to_return; ++i)
{
available.push_back(std::addressof(first_new[i].value));
}
return std::addressof(first_new[to_return].value);
}
else
{
T * result = available.back();
available.pop_back();
return result;
}
}
void deallocate(T * ptr, size_t num_to_free)
{
if (num_to_free == 1)
{
available.push_back(ptr);
}
else
{
::operator delete(ptr);
}
}
// boilerplate that shouldn't be needed, except
// libstdc++ doesn't use allocator_traits yet
template<typename U>
struct rebind
{
typedef plalloc<U> other;
};
typedef T * pointer;
typedef const T * const_pointer;
typedef T & reference;
typedef const T & const_reference;
template<typename U, typename... Args>
void construct(U * object, Args &&... args)
{
new (object) U(std::forward<Args>(args)...);
}
template<typename U, typename... Args>
void construct(const U * object, Args &&... args) = delete;
template<typename U>
void destroy(U * object)
{
object->~U();
}
private:
union value_holder
{
value_holder() {}
~value_holder() {}
T value;
};
std::vector<std::unique_ptr<value_holder[]>> memory;
std::vector<T *> available;
};
Since support for C++11 allocators isn’t universal yet there’s a bit of old boilerplate in there, but overall it’s still pretty compact.
To see how it works let’s look at the deallocate function first: Whenever there’s a large block of memory, I just call regular operator delete. Small blocks of memory go into the available list. The allocate function matches this: Large blocks of memory come from operator new, small blocks come from the available list. When the available list is empty, a new chunk of memory is allocated and all new objects from that chunk get added to the available list.
Should be pretty straight forward. The benefit of this is that the memory from one container gets allocated mostly contiguously. It only makes sense for node based containers though since it falls back to regular operator new and operator delete for large blocks of memory.
One thing that’s a bit ironic is that the only container that fully supports stateful allocators, boost::unordered_map, actually asserts when it tries to move plalloc. The assert comes from a sequence where it does “this->alloc = std::move(other.alloc); ASSERT(this->alloc == other.alloc);” which will always be false for stateful allocators. I consider this a defect in boost::unordered_map and will file a bug for it.
I still had the code for generating the graphs from my sherwood_map post, but this time I didn’t want to spend as much time on generating them so they are less pretty because they have less data points:
| Insert | 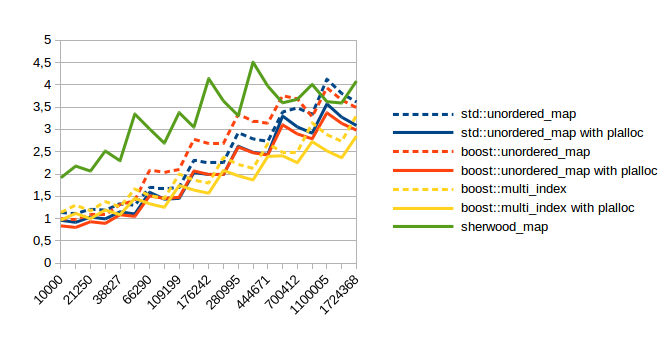 |
| Reserve then Insert | 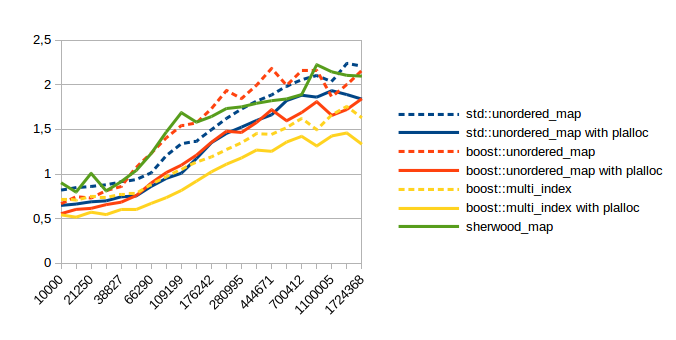 |
| Erase |  |
| Successful Lookup | 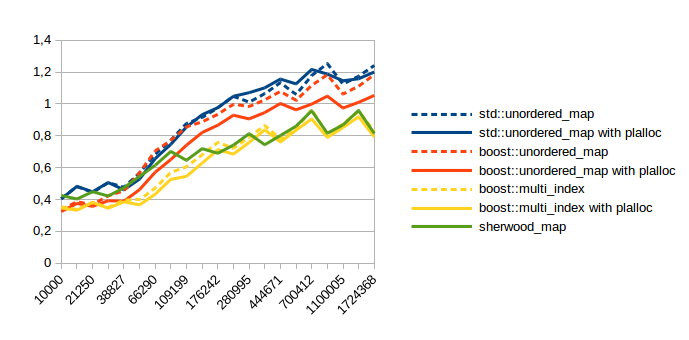 |
| Unsuccessful Lookup | 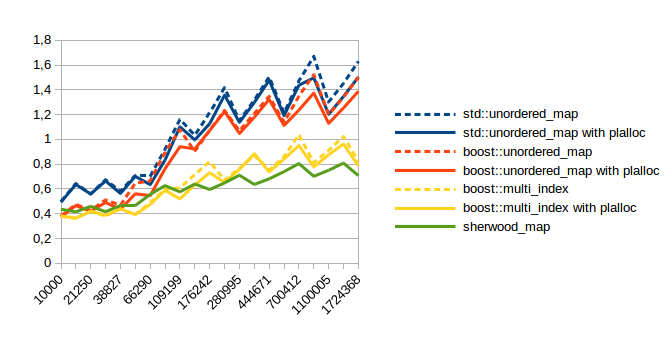 |
In all of these the x axis is the number of items in the container. The y axis doesn’t mean much except to compare relative numbers. Lower numbers are faster. I used maps from int to pair<string, string>.
As you can see using plalloc improves performance in almost all benchmarks. Obviously insert and erase are faster because the code for allocations has simplified a lot, but you probably don’t care about those. (at least I don’t) The lookup performance is probably what matters most, so here are the speed up numbers for those:
| Test | Container | Average speed up with plalloc |
| Successful Lookup | std::unordered_map | 0.3% |
| boost::unordered_map | 11.2% | |
| boost::multi_index | 4.8% | |
| Unccessful Lookup | std::unordered_map | 4.6% |
| boost::unordered_map | 6.5% | |
| boost::multi_index | 3.8% |
boost::multi_index improved enough to beat sherwood_map. Which means I’ll have to spend more time optimizing it…
There’s no graph for sherwood_map with plalloc because it doesn’t make any sense. For sherwood_map plalloc would just be a slower version of std::allocator because sherwood_map is not node based.
Also here are graphs comparing std::map with plalloc to boost::flat_map:
| Successful Lookup |  |
| Unsuccessful Lookup |  |
| Insert | 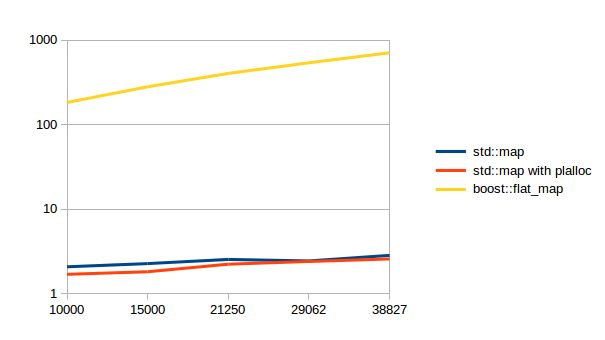 |
| Erase | 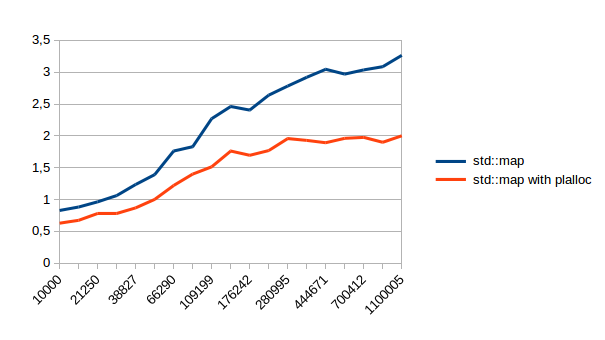 |
The average speed up for successful lookup is 16.8%, and the average speed up for unsuccessful lookup is 6.7%.
A few notes about this: boost::flat_map is still much faster. I didn’t try to find out why this is exactly, but my assumption would be that the processor can predict more than jump ahead of time because it doesn’t have to finish fetching the old memory before it knows where the next jump could go to. I had to make the insert graph be log scale because it’s very slow to insert random values into boost::flat_map. (and Libre Office doesn’t seem to have a way to split an axis) That’s not a problem with the container though, it just shows that you shouldn’t do this. (and it’s not fair to profile the container for something that you shouldn’t do) I left boost::flat_map out of the erase graph because of this. That dent in the unsuccessful lookup is weird. At first I thought it was a measuring error, but it is repeatable. Finding out what it is would take too long though, so It’ll just stay an unsolved mystery. I wouldn’t expect to find this on all machines.
So the benefits of plalloc are:
- It makes code faster
And the downsides are
- It will keep as much memory as you had in your worst case. If your container usually has 1,000 elements but every now and then it has 10,000, then plalloc will always keep enough memory for 10,000
- That remains true even if you clear the container. The memory only gets returned when the container is destroyed
On the other hand whatever method that you were going to use instead of a node based container probably has these same downsides.
One thing that you may notice is that this comes pretty close to turning node based containers into a packed array. It doesn’t exactly, but it goes in the same direction. The biggest downside of plalloc compare to a packed array is that you can’t iterate over the nodes in the order in which they are in the array. But I think you could write an implementation of std::unordered_map which uses a packed array internally and which does allow you to iterate in order. I think the standard allows that…
You can probably use plalloc even if your container doesn’t fully support stateful allocators. Just be careful about copying or moving the containers. I can’t predict what behavior you’d get.
The license for the code is this:
This is free and unencumbered software released into the public domain. Anyone is free to copy, modify, publish, use, compile, sell, or distribute this software, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means. In jurisdictions that recognize copyright laws, the author or authors of this software dedicate any and all copyright interest in the software to the public domain. We make this dedication for the benefit of the public at large and to the detriment of our heirs and successors. We intend this dedication to be an overt act of relinquishment in perpetuity of all present and future rights to this software under copyright law. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. For more information, please refer to <http://unlicense.org/>

I wouldn’t consider the assert() inside Boost to be a bug. Actually, stateful allocators can only compare equal if they can deallocate each other’s memory. In particular, copies of allocators need to compare equal. For that to happen, you need an extra level of indirection in which you put the storage outside the allocator, and use a reference/pointer inside the allocator to that storage. The operator== then simply compares these pointers. It is a bit ugly but it’s the only way to have a C++11 conforming stateful allocator.
The problem with putting the storage outside of the allocator is that then two allocators could be referencing the same storage. At which point I require synchronization between the allocators or else I’d run into threading problems. I’d also make my nice cache behavior much weaker because now content from two different containers could be allocated next to each other.
My allocator is not exactly C++11 standard compliant, but not actually when it comes to move assignment. My move assignment is standard compliant because the standard simply states that the postcondition of “X a1 = move(a);” is that a1 equals the prior value of a. It does not have to equal the value of a after the move, but boost currently asserts that.
Where I’m not standard compliant is actually in my copy constructor. The standard does say that the copy should equal to the original after copy construction. That’s not possible if the allocator owns its memory. It would only make sense if stateful allocators were modeled after shared_ptr, but I think stateful allocators should be modeled after unique_ptr, which is what I do. So I consider that requirement a defect in the standard. (see that’s how you solve problems: everyone is wrong but me ^_^)
Hi, could you give an example how to use your allocator with an unordered_set?
Thanks!
Simone
Sure. Here is a unordered set of strings:
std::unordered_set<std::string, std::hash<std::string>, std::equal_to<std::string>, plalloc<std::string>> a;
a.insert(“foo”);
Let’s hope that the blogging software doesn’t eat my angle brackets.