Transform Matrices are Great and You Should Understand Them
The title of this blog post is obvious for any game programmer, but I notice that people outside of games often write clumsy code because they don’t know how transform matrices work. Especially when people do some simple 2D rendering code, like if you just want to quickly visualize some data in a HTML canvas. People get tripped up on transform math a lot. As an example imagine drawing this simple graph:

It’s just an arbitrary graph with arbitrary numbers, the point is all the layout decisions that happened here: E.g. “Long First Label” extends to the left and pushes everything else over to the right by a bit. If you aren’t organized about how to express your transforms, your code ends up with lots of arbitrary offsets and multipliers. You can’t even calculate where to draw the labels on the y-axis without including an offset for potentially long labels on the x-axis. (and long labels on the y-axis can push over the x-axis, too. Uh-oh) Your first choice for visualization should probably be an existing tool (like I used to generate the graph above) but surprisingly often you’ll want to do something custom, and then you have to worry about transforms.
Game programmers have to do complicated transforms all the time, so they had to get organized about this and the result is the transform matrix. It’s remarkably simple and every programmer should probably know it, just to appreciate its beauty. There are two tricks to transform matrices:
Read the rest of this entry »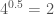 ” (or
” (or  if you only want to apply 10% of the operation) and that seems to work when you’re close to 1, but the further away you are from 1, the more wrong it gets. The answer ends up being to take the median of multiplication, division and exponentiation, but let me further explain the problem first:
if you only want to apply 10% of the operation) and that seems to work when you’re close to 1, but the further away you are from 1, the more wrong it gets. The answer ends up being to take the median of multiplication, division and exponentiation, but let me further explain the problem first: