I Wrote a Fast Hash Table
by Malte Skarupke
As others have pointed out, Robin Hood Hashing should be your default hash table implementation. Unfortunately I couldn’t find a hashtable on the internet that uses robin hood hashing while offering a STL-style interface. I know that some people don’t like the STL but I’ve found that those people tend to write poorer interfaces. So I learn from that by not trying to invent my own interface. You can use this hash table as a replacement for std::unordered_map and you will get a speedup in most cases.
In order to reduce name conflicts I call it sherwood_map, because Robin Hood Hashing.
It’s good to have bad jokes in your code. Other than that name though there are good reasons to prefer this hash table over std::unordered_map.
The main benefit of sherwood_map over unordered_map is that it doesn’t put every element into it’s own heap allocation. Less allocations give you a speedup because a) less allocations and b) more cache hits.
To be up front here is the list of limitations:
- No support for custom allocator propagation. Sorry. I didn’t know about this feature and I learned about it too late. It can be quite a pain to implement so I haven’t done it yet.
- Less exception safety. I assume noexcept moves. If you have that you can throw pretty much anywhere else though.
- Only load factors up to 1
- No iterations within a bucket. I don’t know what that interface is for and it is difficult to implement in Robin Hood Hashing.
- Any modification to the container will invalidate all iterators and references
I think those limitations are OK.
But let’s get to performance tests. Since sherwood_map may have to move elements around when the map gets modified, that would suggest that sherwood_map may be slower than unordered_map for large objects. Because of that I ran all performance tests with a small, (sherwood_map<int, int>) a medium-sized, (sherwood_map<pair<int, string>, pair<int, string>>) and a large (sherwood_map<int, char[512]>) object.
| Clang 3.4 | GCC 4.8.2 | ||||||
| sherwood_map | unordered_map | speedup | sherwood_map | unordered_map | speedup | ||
| insert | small | 113 | 134 | 16% | 106 | 136 | 23% |
| medium | 124 | 150 | 17% | 128 | 152 | 16% | |
| large | 326 | 393 | 17% | 286 | 387 | 26% | |
| reserve insert | small | 72 | 119 | 39% | 72 | 119 | 46% |
| medium | 80 | 131 | 39% | 82 | 136 | 39% | |
| large | 147 | 342 | 57% | 114 | 335 | 66% | |
| erase | small | 137 | 196 | 30% | 149 | 199 | 25% |
| medium | 205 | 225 | 9% | 205 | 231 | 11% | |
| large | 347 | 361 | 4% | 353 | 345 | -2% | |
| lookup | small | 228 | 361 | 37% | 230 | 473 | 52% |
| medium | 243 | 436 | 44% | 242 | 634 | 62% | |
| large | 277 | 571 | 51% | 263 | 709 | 63% | |
| modify | small | 384 | 459 | 16% | 388 | 508 | 24% |
| medium | 549 | 519 | -6% | 530 | 577 | 8% | |
| large | 1120 | 724 | -55% | 1279 | 750 | -71% | |
Explanations for the tests:
- insert inserts a bunch of elements into a map
- reserve insert is the same test but I call reserve() before inserting the elements
- erase builds a map and then erases all elements again
- lookup builds a map and then performs many lookups where most of the lookups will fail
- modify builds a map and then erases one element and adds one new element over and over again
In all of the non-insert tests I call reserve() when building the map. But I use a different number of elements for each test, so the overhead for building the map is not always the same. I also fill up the map until it has 85% load factor, which is the default max_load_factor() for sherwood_map. The default max_load_factor() for unordered_map is 100%, but for comparisons sake I use the same value for both.
The results are kind of what I expected. The biggest speed improvements are for lookups, and for when inserting into a map that has reserved enough space to fit all elements. I didn’t measure this exactly, but I expect that the main reason for the improved lookup time is that there are fewer pointer indirections, and the reason for the improved insert time is that sherwood_map doesn’t need to do new heap allocations.
I was surprised though to see that sherwood_map also performs better in almost all other areas. Only when there are many modifications to the map is unordered_map faster. Note though that this is not the case if you modify values that are already stored in the map. Only when you erase objects and add new objects is unordered_map faster. (updating existing objects is as fast as performing a lookup)
I also did a brief test to see how much memory each map is using: When storing one million objects in a unordered_map<int, string> my application uses 39 MiB of memory. When storing one million objects in a sherwood_map<int, string> my applications uses 27.6 MiB of memory. I expect that the reason for this is that unordered_map has more overhead for every object stored in the map. I did not modify the max_load_factor of the map for this test, so unordered_map uses a max_load_factor of 1, where sherwood_map uses a max_load_factor of 0.85.
One thing that I’m kind of embarrassed about (because I just did a big post about this) is that sherwood_map compiles more slowly than unordered_map. I know why it compiles more slowly and I know how to change it, but it requires some non-trivial changes to the structure of the map. Maybe I’ll do that when I support allocator propagation. But C++ does make it difficult to predict how fast or slow your code will compile… (in my case it’s actually because std::swap compiles slowly, who would have thought…)
So when should you use unordered_map? If you plan to do lots of modifications to the map (lots of erases and insertions of new objects) or if you need your iterators and references to not be invalidated. Otherwise using Robin Hood Linear Probing seems to be a better alternative.
And here is a link to the github files.
edit:
gnzlbg in the comments pointed me to a Joaquín M López Muñoz blog where he had done performance comparisons for hashtable implementations. I ran his same benchmarks and the results are… embarrasing. Let’s start with the results:
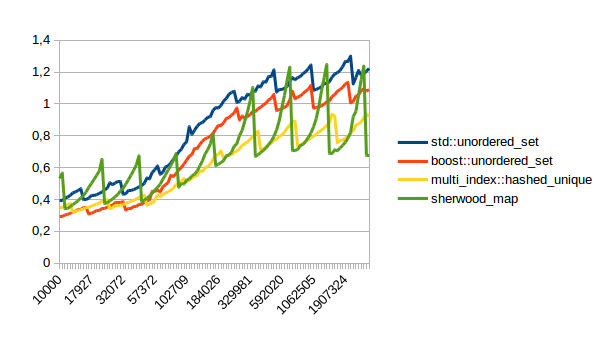
Inserting elements:

Reserving and then inserting elements:
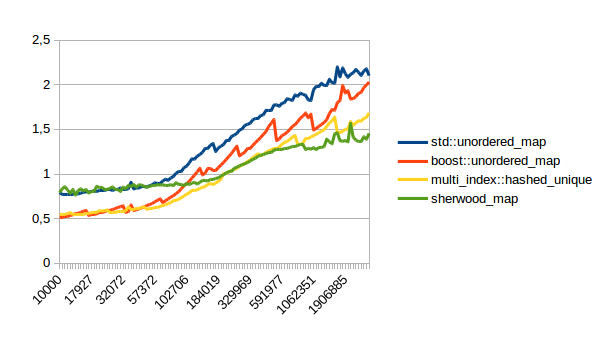
Erasing elements:
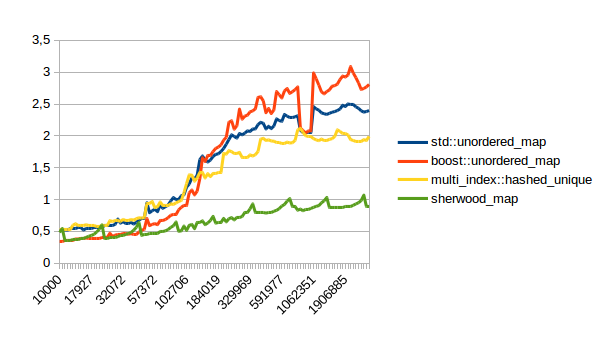
Successful lookups:
Unsuccessful lookups:
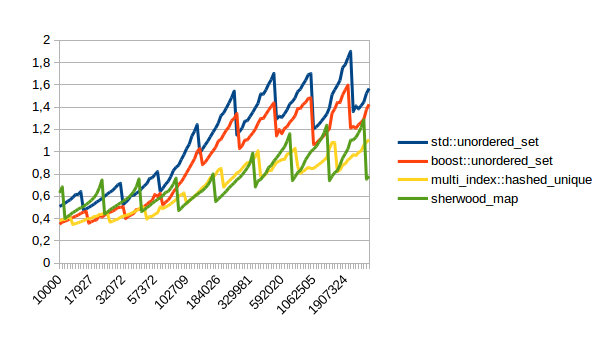
In all of these lower numbers are better. So sherwood_map doesn’t do terribly, but unfortunately the right hand side of that graph doesn’t really count. The left hand side is interesting because at least for me most maps have few elements. Unfortunately I ran my comparison above on the right hand side of the graph. I didn’t do that intentionally, I just ran a test that took long enough to be easy to measure.
So what do I take from this? Time to optimize sherwood_map :-). I spend all of my time on the calculation for the bucket of a given index. The way you find out when to stop iterating in Robin Hood Linear Probing is to look at how far you are from the initial bucket of a given element. When you find an element that’s less steps away from its initial bucket than your element is from your initial bucket, then you can stop iterating because you know that your object is not in the map. Unfortunately that means that as you’re iterating you keep on having to calculate the initial bucket of elements that you walk past. So I’ll play around with caching that calculation. If that doesn’t work I could also change my bucket count to be a power of two. That’s frowned upon for hashtables because it increases clustering but the increased clustering may be worth it if iterating over those clusters to find your element is cheap.
I’ll probably write a new blog post once I’ve done that.

Have you compared your results with those of Boost associative containers?
Joaquín M López Muñoz has a very in-depth survey in [0] and related posts.
[0] http://bannalia.blogspot.de/2014/01/a-better-hash-table-clang.html
I have not compared with boosts associative containers. I will run the code from his website and update the blog post. Unfortunately that code takes a while because it runs quite a lot of tests to generate those pretty graphs. I will let my machine run for a while and report back with the results.
So far it looks like unordered_map beats sherwood_map for small numbers of elements, and sherwood_map is faster for large numbers of elements. Unfortunately for me, “large” in this case really means quite large, meaning several hundred thousand. Which would suggest that unordered_map might be better for most cases where you have small maps.
It would also suggest that my table above is not super representative of performance because I ran my tests with one million elements. The only reason I did that was that I needed to make the test long enough where you can measure an actual difference. It’s no good if the test takes 1ms for unordered_map and 1ms for sherwood_map.
I will update once I’ve actually run all the tests, which will probably be this evening. (or tomorrow if I don’t get around to finishing this this evening)
Hi, I’ve updated the blog post with the performance measurements from his website. Turns out sherwood_map doesn’t actually do too well for small amounts of elements. I will try to fix that though and then write a new blog post.
I like Robin Hood hashing, and I don’t really have any comments there besides that I think it would be a fairer comparison to compare sherwood_map to another flat container, so it’s easy to see what speed is attributable to open addressing and what is attributable to Robin Hood hashing.
The one thing I would mention is that part of my dislike for the STL container interface is that it takes 1,000 lines of code to implement this, with heavyweight includes like and , and without debug iterators, which I would consider a requirement for a container that invalidates iterators on every update. In general, the boilerplate both contains bugs (there’s an std::forward in there where Args is not a template parameter of the function, which doesn’t actually do forwarding), and deflects eyes from the actual logic. I started typing up this before it occurred to me that I had failed to look at the remove implementation because I was distracted by the sexy (&&, , and ::). And I think your erase has a bug: As Sebastian mentions, you can’t erase elements by zapping the hash, you need to keep a tombstone from which you can read the probe distance so you don’t break lookup for elements after the deleted entry.
I don’t have a better interface than the STL one that intends to address the same use cases, so feel free to ignore my whining, but I thought I’d bring it up.
Yeah stl containers are big. And I don’t feel super good about bringing in , but that is where std::hash lives. I don’t feel as bad about though. I rarely have a file where I don’t use an algorithm, so this doesn’t add any overhead for me.
The case where I use std::forward where the Args are not a template parameter of the function happens to actually come out correctly. Yes, it doesn’t do perfect forwarding (if the function takes by value then temporaries get created) but it will move values and rvalue references, and it will not move lvalue references, which is exactly what I want in that case. Thinking about it though, I could just change that code to do perfect forwarding and I don’t think that there would be any problems. (except for more confusing error messages on type mismatches)
As for the erase function: I don’t actually use the algorithm described in the post that I linked to. Instead of placing tombstones I shift all elements that want to be in the newly vacated bucket over by one position. This means that you’re moving a bunch of items around when erasing, but the contents of the container are much more predictable and you need to handle one less special case. Unfortunately I don’t remember where I have that algorithm from, but it is described somewhere on the Internet.
The erase code is the code where I had the most bugs while developing, but that just means that now it’s the most tested code of the container, so I’m pretty sure it’s correct. I ran this map through all the same unit tests that boost::unordered_map uses, and boost is good enough for me :-).
Hmm, that’s an interesting tradeoff. I like not having tombstones, and it makes sense to me to optimize for reads rather than writes (although maybe you would do something else if implementing a hash set rather than a hash map). I never was fond of the fact that you had to reallocate a hash table eventually after deleting elements from it. That alone might get me to try this algorithm.
(On both our posts, WordPress ate text inside angle brackets. Yay for blogging software.)
For the record, Sebastian himself actually later posted that his tombstone approach caused degraded performance if there were a lot of deletions and re-insertions, and that backward-shift-on-deletion tended to work better.